![[CS][데이터베이스설계와질의] Chapter01. Introduction to Database Systems](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbmAkWx%2FbtsxslR56Tc%2F2lK2u7uSgFvM6Hm7CkVp10%2Fimg.png)
What is a DBMS?
- 데이터 vs 정보 vs 지식
- 세가지 모두 데이터에서 파생된 개념
- 데이터 : 서술/관찰/측정된 날 것 그대로의 사실, 모든 것이 될 수 있음
- 정보 : 준비되고 조직된 데이터, 사람이 사용하기 위해 다듬고 만든 것
- 지식 : 실제 의사결정을 위해 사용되는 데이터/정보/규칙, 인간의 법칙까지 포함
- 데이터베이스 : 관련된 데이터의 크고 통합된 모음
- 통합(Integrated) : 개념적으로 보았을 때 데이터가 퍼져있지 않고 모아져 있음
- DBMS(Database Management System)
- 데이터베이스를 저장하고 관리하도록 설계된 소프트웨어 패키지
- DB에서 일어나는 일을 DBMS에게 맡김
- DB를 관리하기 위한 체계
- 우리가 만드는 프로그램은 DBMS를 통해 Disk 저장소에 접근 = DBMS approach

Why use a DBMS?
- 데이터 독립성 : 응용 프로그램들은 데이터의 표현과 저장에 대한 세부사항에 영향을 받지 않는 것이 이상적, DBMS는 이러한 세부사항을 은닉하는 데이터의 추상적인 관점 제공
- 효율적인 액세스
- 애플리케이션 개발 시간 단축
- 데이터 무결성 및 보안
- 균일한 데이터 관리 : 데이터에 대한 관리를 중앙 집중화
- 동시 액세스, 충돌로부터의 복구
Data Models
- Data Model
- 데이터를 설명하기 위한 개념의 모음
- 고수준의 데이털르 기술하는 구성자들의 집합
- DBMS가 사용자로 하여금 저장될 데이터를 데이터 모델에 의해 정의할 수 있게 함
- Schema
- 주어진 데이터 모델을 사용하여 특정 데이터 모음을 설명하는 것
- 틀, 데이터 개개인의 표현 X
- 각 field(attribute, raw)의 이름과 타입, 명
- "데이터 모음이 이런 식입니다"라고 표현해둔 것
- DB에서 데이터가 구조화 되는 방식을 정의
- Instance
- 정의된 schema에 따라 DB에 실제로 저장된 값
- Relational model of Data (관계형 데이터 모델)
- 오늘날 가장 널리 사용
- 레코드들의 집합
- 주요 개념 : 관계, 기본적으로 행/열이 있는 테이블
- Relation한 컨셉으로 데이터 표
- 모든 관계에는 열 또는 필드를 설명하는 스키마 존재
History of Data Models
- 1960년대 초반
- Network Model
- Node&Edge로 세상 표현 ( ≒ graph )
- By Charles Bachman at GE
- CODASYL (Conference On Data Systems Language)
- 1960년대 후반
- Hierarchical Model
- Root 존재 ( ≒ tree )
- IMS by IBM
- SABRE airline reservation system
- 1970년대
- Relational Model
- By Edgar Codd at IBM
- SQL from IBM System R
- 1980년대 후반 & 1990년대 초반
- Extended(Object) Relational Model : 데이터를 테이블로 보는, Relational인데 Object가 수식어
- Object Oriented Model : 객체 지향
- 1990년대 후반
- Data Warehousing, Data Mining, Distributed DB, Web Database, ERP(Enterprise Resource Planning) 등
- ER(Entity-Relationship Model)
- Semantic Data Model vs Record based Model
- 어떤 데이터 모음이 필요한지 탐색하는 것
Levels of Abstraction
- Schema를 Level로 만들자
- 적어도 3개 Level이 표준
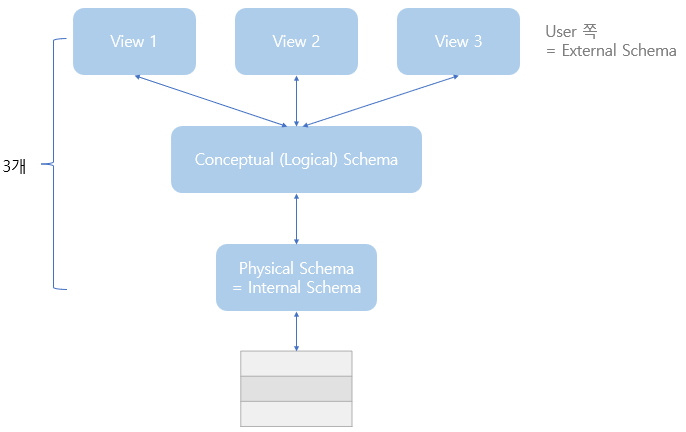
- 사용자가 데이터를 보는 방식을 설명한 그림
- External schema
- 사용자의 View
- 개별 사용자 입장에서 DB의 논리적 구조를 정의한 것
- 사람마다 보는 View는 다르지만 사실 보는 대상(Conceptual Schema)은 동일
- 필요한 것만 보기, User가 굳이 다 볼 필요는 없으니까
- 동일한 데이터에 대해 서로 다른 관점 정의 허용
- 최종 사용자의 요구들에 의해 방향이 정해짐
- 하나의 DB System에는 여러 개의 External schema 존재 가능
- 하나의 External schema를 여러 개의 응용 프로그램이나 사용자가 공용 가능
- Conceptual schema
- 전체적인 View
- 데이터의 전체 논리적 구조를 정의
- 얘로 DB를 바라 봄
- 개념적 파악 가능
- 모든 Relation 기술
- 하나의 DB에는 하나의 Conceptual shema만 존재
- Physical schema
- = Internal schema
- 추가적인 저장의 세부사항들 명시
- 사용되는 파일과 인덱스를 설명 (내부 레코드 형식, 물리적 순서 등)
- 물리적 저장 장치의 입장에서 본 DB 구조 (물리적으로 어떻게 저장/관리 되어야 하는지)
- Conceptual schema를 보조기억장치에 물리적으로 구현하기 위한 방법 기술
- 하나의 DB에는 하나의 Physical shema만 존재
- Schema는 DDL로 정의된다 (DDL : Data를 Definition 하는 Language)
- Data는 DML로 수정/쿼리된다 (DML : Data를 manipulatie 하는 Language)
Example : University Database
- External Schema (View)
- Course_info(cid:string, enrollment:integer)
- Conceptual schema
- Students(sid: string, name: string, login: string, age: integer, gpa:real)
- Courses(cid: string, cname:string, credits:integer)
- Enrolled(sid:string, cid:string, grade:string)
- Physical schema (Internal Schema)
- Relations stored as unordered files
- Students, Courses 릴레이션들의 첫번째 필드에 대한 인덱스를 생성
Data Independence
- 만약 DBMS가 없다면, 응용프로그램은 DB에 종속
- 이렇게 안하려고 DBMS 생성 = Data Independence
- 응용 프로그램이 데이터의 구성과 저장 방식의 변화로부터 격리되어 있다는 뜻
- 데이터 추상화를 통해 달성 → 특히 Conceptual & External schema가 독립성을 유지하기 위해 큰 역할
- Layer을 만들면 얻는 효과, 수정 시 다 갈아엎지 않게
- DBMS 사용의 가장 중요한 효과 중 하나
- 데이터가 구조화되고 저장되는 방식으로부터 떨어진 애플리케이션
- Logical data independence : 데이터의 논리적 구조 변경 또는 저장될 relation들의 선택의 변경로부터 보호
- Physical data independence : 데이터의 물리적 저장의 세부적인 변화로부터 보호, By Conceptual schema
- 위 두 가지는 Layer가 3개이기 때문에 가능한 것
Transaction : An Execution of a DB program
- 일처리의 단위
- DB 작업(읽기/쓰기) atomic한 순서
- atomic ≒ unit = 쪼갤 수 없는 단위
- transaction이 시작될 때 DB가 consistent한 경우, 완전히 실행된 각 transaction은 DB를 consistent state로 유지해야 합니다 ★★★
- consistent state가 1순위, 무결성(일관성)을 위해
- 각 operation까지 consistency와 integrate는 보장되지 않음 → transaction에서 보장 (DBMS가 처리)
- transaction 중간에는 consistency를 논하지 않음
Concurrency Control
- 동시성 제어
- DBMS의 우수한 성능을 위해서는 사용자 프로그램의 동시 실행이 필수적
- Disk Access가 빈번하고 상대적으로 느리기 때문에
- 여러 사용자 프로그램에서 동시에 작업하여 CPU hummning을 유지하는 것이 중요
- 다른 사용자 프로그램의 Inerleaving 작업은 불일치를 초래할 수 있음
- DBMS는 이러한 문제가 발생하지 않도록 보장
- 사용자가 단일 사용자 시스템을 사용하는 것처럼
- scheduling, locking 등
Structure of a DBMS
- 일반적인 DBMS는 Layered architecture
- 각 시스템에는 고유한 변화 존재

- 위 그림에는 동시성 제어 및 복구 구성 요소 표현 X
- 위 그림은 여러 가지의 가능한 architecture 중 하나
- Query = Bring a Question
- Buffer : 중간 임시 저장소
- 위에서 아래로 component 기반 passing
Summary
- DBMS : 대규모 datasets을 유지, 쿼리하는데에 사용
- 장점 : 시스템 충돌로부터의 복구, 동시 액세스, 빠른 애플리케이션 개발, 데이터 무결성 및 보안 등
- 추상화의 Level은 데이터의 독립성을 제공
- DBMS는 일반적으로 Layered architecture을 가짐
- DBA는 책임감 있는 업무를 수행하고 보수가 높음
- DBMS R&D는 가장 광범위한 것 중 하나이며, CS에서 가장 흥미로운 분야
'Computer Science > Database Design & Query Languages' 카테고리의 다른 글
| [CS][데이터베이스 시스템 3판] Chapter03. The relational Model (0) | 2023.10.18 |
|---|---|
| [CS][데이터베이스설계와질의] Chapter02. The Entity Relationaship model (0) | 2023.10.18 |
| [CS][데이터베이스설계와질의] Chap05. SQL (0) | 2023.10.16 |
| [CS][데이터베이스설계와질의] Chapter00. Intro-Data-Inf-Know (0) | 2023.10.09 |
| [CS][데이터베이스설계와질의] "데이터베이스 설계와 질의" 수강을 시작하며 (0) | 2023.10.09 |