![[SQLD/IT자격증] SQLD 2과목 "SQL 기본" 이론 정리](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F6Y23g%2FbtsI4RMF3oK%2FLztTdUC5zuazEMky5hbU61%2Fimg.png)
SQL 2과목 SQL 활용 중 SQL 기본
SQLD(SQL개발자) 시험의 2과목인 SQL 활용 중 SQL 기본에서 요구하는 항목은 아래 사진과 같습니다.

아래 유튜브 채널 강의를 들으며 정리하였습니다.
[개정판] SQLD 2과목 PART1. SQL 기본(2024년 신유형 반영) #관계형데이터베이스 #SELECT #함수 #조인 - YouTube
데이터베이스와 DBMS
- 데이터베이스 : 데이터의 집합, 형식을 갖추지 않아도 된다.
- DBMS : 데이터를 효과적으로 관리하기 위한 시스템(소프트웨어), 각각의 파일보다 시스템적으로 작동하게 만든 시스템, 예로 ORACLE, MYSQL 등이 있다.
관계형 데이터베이스 구성 요소
- 계정 : 데이터의 접근 제한을 위한 여러 업무/시스템 별 계정이 존재해야 한다
- 테이블 : DBMS의 DB 안에 데이터가 저장되는 형식
- 스키마 : 테이블이 어떤 구성으로 되어 있는지, 어떤 정보를 가지고 있는지에 대한 기본적인 구조를 정의
테이블
테이블은 데이터의 저장 단위로 행과 열을 가지는 2차원 구조이다.
테이블의 특징은 아래와 같다.
- 하나의 테이블은 반드시 하나의 유저(계정) 소유여야 한다. 즉 여러 소유자가 하나의 테이블을 소유할 수 없다. 하지만, 여러 유저가 조회할 수는 있다.
- 테이블 간의 관계는 1:1, 1:N N:M 관계를 가진다.
- 테이블 명은 중복될 수 있다. 하지만, 소유자가 다를 경우에는 같은 이름으로 생성할 수 있다.
- 데이터는 행 단위로 입력되고 삭제된다. 수정은 값의 단위로 가능하다.
관계형 데이터베이스의 특징
- 데이터의 분류, 정렬, 탐색하는 속도가 빠르다.
- 신뢰성이 높다.
- 데이터 무결성을 보장한다.
- 기존의 작성된 스키마를 수정하기 어렵다.
- 데이터베이스의 부하를 분석하는 것이 어렵다.
데이터 무결성(Integrity)
데이터의 무결성이란 데이터에 결점이 없다는 의미로 데이터의 정확성과 일관성을 유지하고 데이터에 결손과 부정합이 없음을 보증하는 성질이다. 데이터베이스에 저장된 값과 그것이 표현하는 현실의 비즈니스 모델의 값이 일치하는 것을 이야기 한다. 이 성질은 DBMS에서 중요한 기능을 한다.
데이터 무결성의 종류
- 개체 무결성 : 테이블의 기본키를 구성하는 컬럼은 NULL이나 중복값을 가질 수 없다.
- 참조 무결성 : 외래키 값은 NULL이거나 참조 테이블의 기본키 값과 동일해야 한다.
- 도메인 무결성 : 주어진 속성 값이 정의된 도메인에 속한 값이어야 한다.
- NULL 무결성 : 특정 속성에 대해 NULL을 허용하지 않는 특징을 가질 수 있다.
- 고유 무결성 : 특정 속성에 대해 값이 중복되지 않는 특징을 가질 수 있다.
- 키 무결성 : 하나의 관계에 적어도 하나의 키가 존재해야 한다. (조인키)
SQL (Structured Query Language)
SQL은 관계형 DB에서 데이터 조회, 조작과 DBMS 시스템 관리 기능을 명령하는 언어이다. 데이터 정의(DDL, 데이터 조작(DML), 데이터 제어 언어(DCL) 등으로 구분할 수 있으며 대소문자를 구분하지 않는다.
SQL 종류
| 구분 | 종류 | 설명 |
| DDL (Data Definition Language) | CREATE, ALTER, DROP, TRUNCATE | 구조 자체를 변동 취소 불가능(AUTO COMMIT) |
| DML (Data Manipulation Language) | INSERT, DELETE, UPDATE, MERGE | 데이터를 변경 |
| DCL (Data Control Language) | GRANT, REVOKE | 데이터에 대한 권한을 제어 |
| TCL (Transaction Control Language) | COMMIT, ROLLBACK | 트랜잭션을 제어 |
| DQL (Data Query Language) | SELECT |
TRUNCATE는 데이터 구조는 지우지 않지만, 데이터를 모두 지우는 명령어로 취소가 불가능한 AUTO COMMIT이기 때문에 DDL이다.
SELECT문
아래와 같이 6개의 절로 구성되어 있으며 각 절의 순서대로 작성해야 한다.
SELECT 절은 SELECT 문장을 사용하여 불러올 컬럼명이나 연산결과를 작성하는 절이다.
SELECT * | 컬럼명 | 표현식
FROM 테이블명 | 뷰명
WHERE 조회 조건
GROUP BY 그룹핑 컬럼명
HAVING 그룹핑 필터링 조건
ORDER BY 정렬 컬럼명하지만 SELECT문의 내부 파싱 순서는 작성 순서와는 다르며 FROM → WHERE → GROUP BY→ HAVING → SELECT → ORDER BY 순서대로 실행된다.
SELECT문의 특징
- SELECT절에서 표시할 대상 컬럼에 별칭(Alias)을 지정할 수 있다.
- 대소문자를 구분하지 않아도 된다.
별칭(Alais)
- 컬럼명 대신 출력할 임시 이름을 지정하는 것으로 SELECT 절에서만 정의가 가능하고 원본 컬럼명은 변경되지 않는다.
- 컬럼명 뒤에 AS와 함께 컬럼의 별칭을 작성하면 된다. (생략 가능)
- SELECT문보다 늦게 수행되는 ORDER BY 절에서만 별칭을 사용할 수 있다.
- 한글을 사용할 수 있다.
- 이미 존재하는 예약어는 사용할 수 없다.
- 별칭에 공백을 포함하거나, 별칭에 특수문자를 포함하거나(_제외), 별칭 그대로 전달할 경우(대소문자 구분)에는 " "를 작성해야 한다.
SELECT절
- * 표현을 통해 테이블 내 전체 컬럼을 불러올 수 있다.
- * 표현을 통해 테이블 내 전체 컬럼을 불러올 수 있다.
- 표현식이란 원래의 컬럼명을 제외한 모든 표현 가능한 대상이다. (예: SAL * 1.1)
FROM절
- 데이터를 불러올 테이블명 또는 뷰명을 작성한다.
- 뷰 : 테이블의 일부를 볼 수 있는 미리보기로 테이블과 동일하게 데이터를 조회할 수 있는 객체이지만 테이블처럼 실제 데이터가 저장된 것이 아니다.
- 불러올 테이블명을 여러 개 전달 가능하여 , 로 구분하면 된다. 하지만 조인 조건 없이 테이블명만 나열하게 되면 카타시안 곱이 발생할 수 있기 때문에 주의해야 한다.
- 테이블 별칭을 선언할 수 있다. ORACLE은 AS 사용이 불가하고 SQL Server는 사용 및 생략이 가능하다. 테이블 별칭 선언 시 컬럼은 모두 테이블 별칭으로 작성해야 한다.
- 만약 데이터를 조회하기 위함이 목적이 아니라 표현하기 위함이 목적이라면 FROM 절이 필요없을 수 있는데 ORALE에서는 FROM 절 생략이 불가능하기 때문에 더미 테이블인 DUAL 테이블을 선언해야 하다.하지만 SQL Server에서는 생략이 가능하다.
WHERE절
- 필터링을 위해 조건을 작성하는 절
- 여러 조건을 동시에 전달할 수 있다. (AND, OR로 조건을 연결하면 된다.)
- NULL 조회 시 IS NULL/IS NOT NULL 연산자를 사용해야 한다.
- 문자나 날짜 상수 표현 시에는 ' ' 을 사용해야 한다.
- ORACLE은 문자 상수의 경우에는 대소문자를 구분한다.
- MYSQL은 문자 상수의 대소문자를 구분하지 않는다.
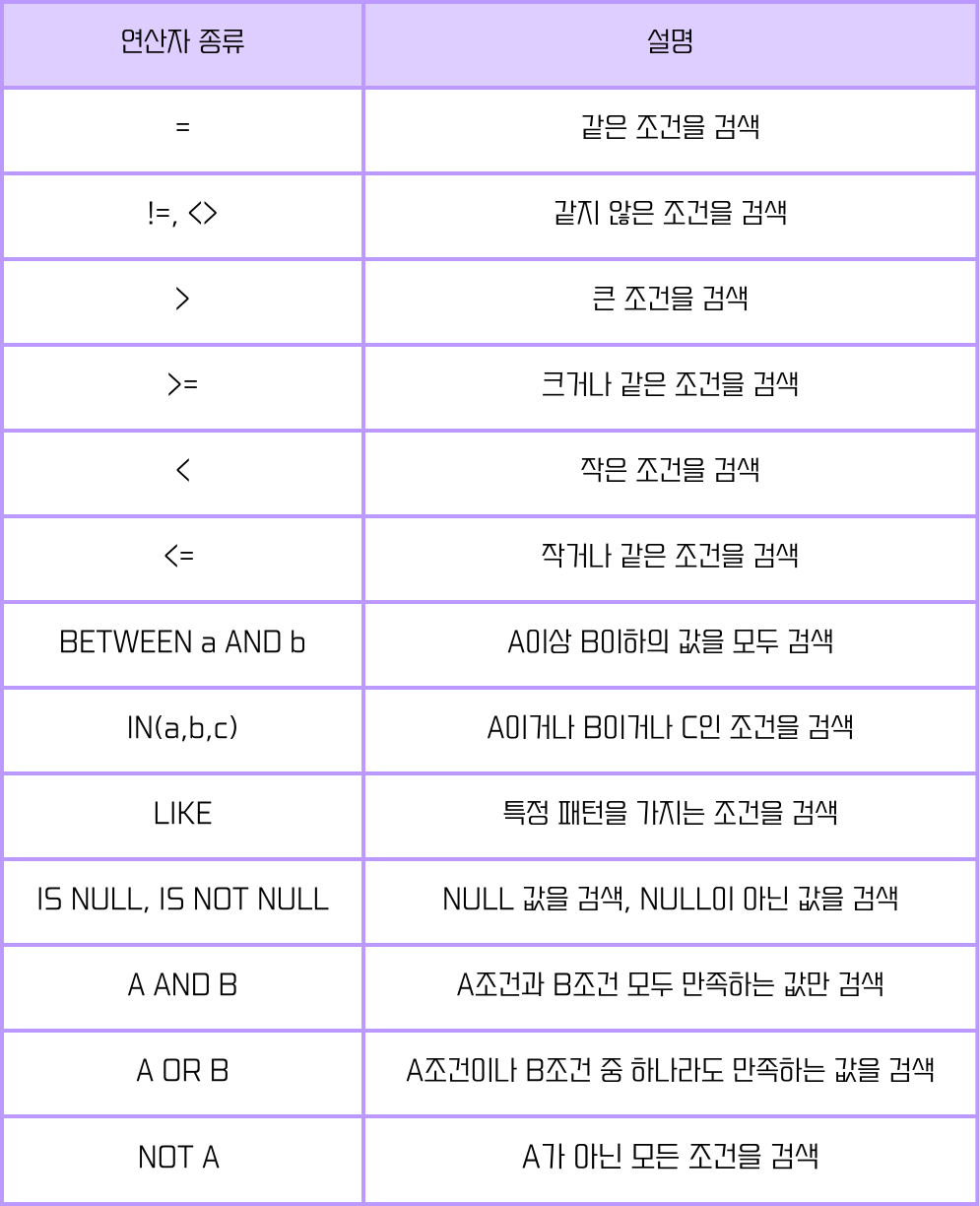
IN 연산자는 포함연산자로 여러 상수와 일치하는 조건을 전달할 때 사용한다. 상수는 괄호로 묶어 동시에 전달하면 된다. 아래 SQL문의 결과값이 같다.
SELECT EMPNO
FROM EMO
WHERE ENAME = 'SMITE' OR ENAME = 'SCOTT';
SELECT EMPNO
FROM EMO
WHERE ENAME IN ('SMITH', 'SCOTT');BETWEEN A AND B 연산자는 이상, 이하로 생각하면 된다. 숫자뿐만 아니라 문자, 날짜도 대소비교 가능하다.
LIKE 연산자는 정확하게 일치하지 않아도 되는 패턴 조건 전달 시에 사용하낟.
- % : 자리수 제한 없는 모든의 의미
- _ : _ 하나 당 한 자리수 의미
- ENAME LIKE 'S%' : 이름이 S로 시작하는, S 한 글자여도 가능
- ENAME LIKE '%S%' : 이름에 S를 포함하는
- ENAME LIKE '%S' : 이름이 S로 끝나는
- ENAME LIKE '_S%' : 일므의 두번째 글자가 S인
- ENAME LIKE '__S__' : 이름의 가운데 글자가 S이면서 이름이 5글자인
NOT 연산자는 조건 결과의 반대집합을 출력하며 주로 NOT IN, NOT BETWEEN A AND B, NOT LIKE, NOT NULL를 사용한다.
GROUP BY절
- 각 행을 특정 조건에 따라 그룹을 분리하여 계산하도록 하는 구문식
- 여러 컬럼을 전달 가능하다.
- 만약 그룹 연산에서 제외할 대상이 있다면 미리 WHERE절에서 해당 행을 제외하면 된다.
- 그룹에 대한 조건은 WHERE절에서 사용할 수 없다.
- GROUP BY절을 사용하면 데이터가 요약된다.
##부서별 급여 총 합과 평균을 출력하는 SQL문
SELECT DEPARTMENT_ID, SUM(SALARY), ROUND(AVG(SALARY))
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;##GROUP BY의 잘못된 사용
SELECT DEPTNO, MAX(SAL), ENAME
FROM EMP
GROUP BY DEPTNO;
→ ENAME은 요약된 정보가 아니기 때문에 SELECT할 수 없다.
→ GROUP BY절에 명시되지 않은 컬럼은 SELECT절에 작성이 불가능하다.
HAVING 절
- 그룹 함수 결과를 조건으로 사용하는 절
- WHERE을 사용해서는 그룹을 제한할 수 없기에 사용
- 일반 조건의 경우 WHERE절과 HAVING절에서 모두 사용할 수 있는데 그럴 경우에는 WHERE절에서 실행하는 것이 실행순서가 앞서기 때문에 권장된다.
- 내부 실행 순서가 SELECT절보다 앞서기 때문에 SELECT절에서 선언된 별칭 사용이 불가
ORDER BY절
- 출력되는 행의 순서를 변경하고 싶을 때 사용
- 여러 개의 컬럼을 전달 가능
- 명시된 컬럼 순서대로 정렬
- ASC(오름차순), DESC(내림차순)으로 명시 (ASC가 기본값이다.)
- 유일하게 SELECT절에서 정의한 별칭을 사용 가능
- SELECT절에 선언된 칼럼 순서대로의 숫자도 작성 가능
#숫자값을 문자값으로 바꾼 뒤 정렬
SELECT TO_CHAR(SAL) AS SAL
FROM EMP
WHERE SAL <= 2000
ORDER BY SAL;
#결과
1100
1250
1300
1500
950#SELECT절 컬럼 순서를 사용한 정렬
SELECT EMPLOYEE_ID, FIRST_NAME, HIRE_DATE
FROM EMPLOYEES
ORDER BY 3;
→ HIRE_DATE를 기준으로 과거 날짜~현재 날짜 순서대로 오름차순 정렬복합 정렬이란 먼저 정렬한 값의 동일한 결과가 있을 경우 추가적으로 정렬하는 기능이다.
#SALARY의 값을 기준으로 내림차순으로 먼저 정렬 후에 동일한 SALARY 값이 있을 경우 HIRE_DATE 값으로 오름차순 정렬한다.
SELECT FIRST_NAME, SALARY, HIRE_DATE
FROM EMPLOYEES
WHERE SALARY>10000 AND DEPARTMENT_ID=90
ORDER BY SALARY DESC, HIRE DATE;NULL은 ORACLE에서는 기본적으로 마지막에 배치하고 SQL Server은 처음에 배치한다. 또한 ORACLE에서는 NULLS LAST 혹은 NULLS FIRST를 명시하여 NULL 정렬 순서를 변경할 수 있다.
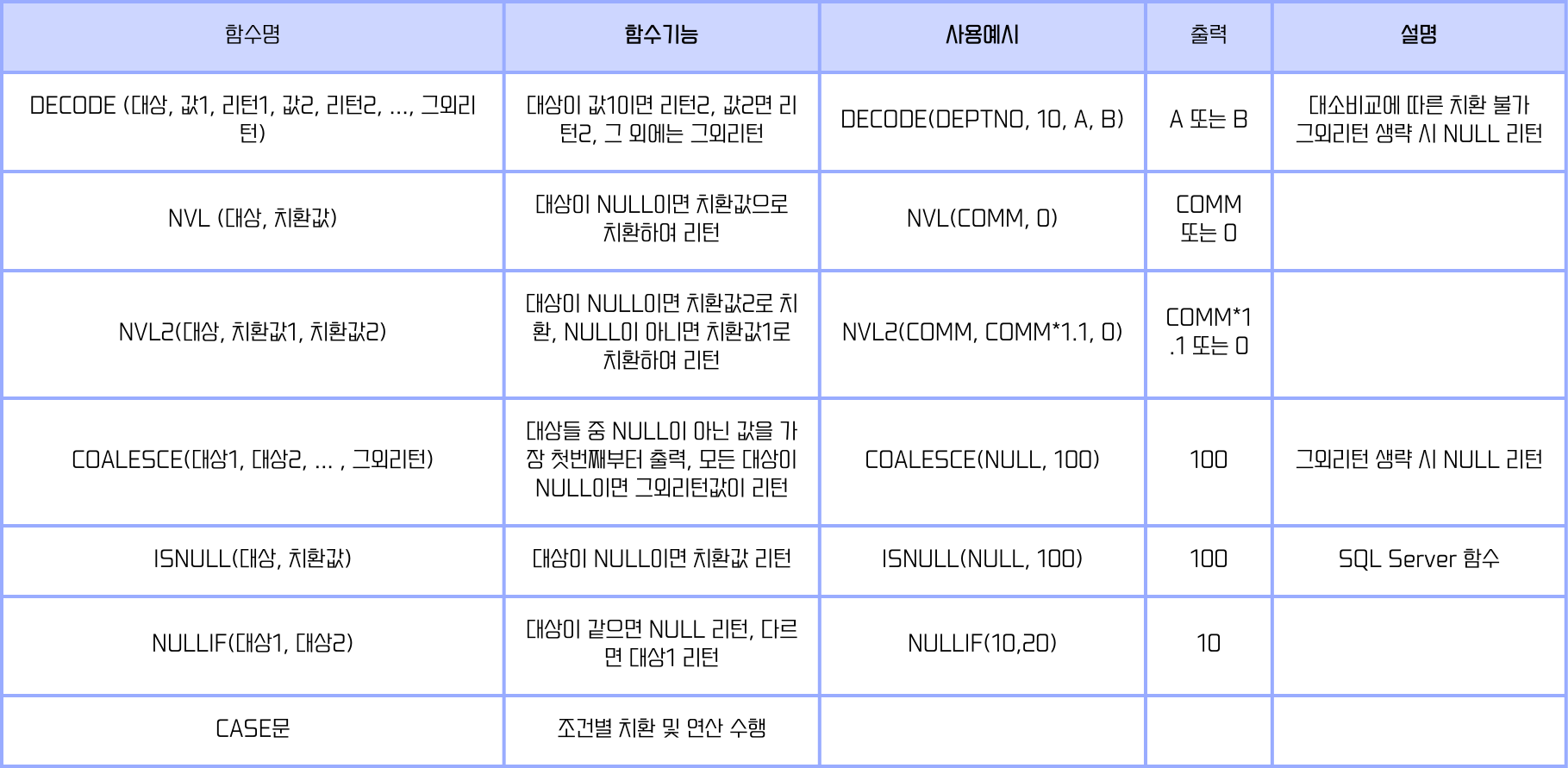
함수
함수는 FROM절을 제외한 모든 절에서 사용 가능하다.
함수의 기능
- 기본적인 쿼리문을 더욱 강력하게 해준다.
- 데이터의 계산을 수행한다.
- 개별 데이터의 항목을 수정한다.
- 표시할 날짜 및 숫자 형식을 지정한다..
- 열 데이터의 유형을 변환한다.
입력값의 수에 따른 함수의 분류
- 단일행 함수 : INPUT : OUTPUT = 1 : 1
- 복수행 함수 : 여러 건의 데이터를 동시에 입력 받아 하나의 요약값을 리턴하는 함수 (=그룹함수, 집계함수)
입출력값의 타입에 따른 함수의 분류
- 문자형 함수
- 문자열의 결합, 추출, 삭제 등을 수행한다.
- 단일행 함수 형태이다.
- OUTPUT은 대부분 문자값이다.

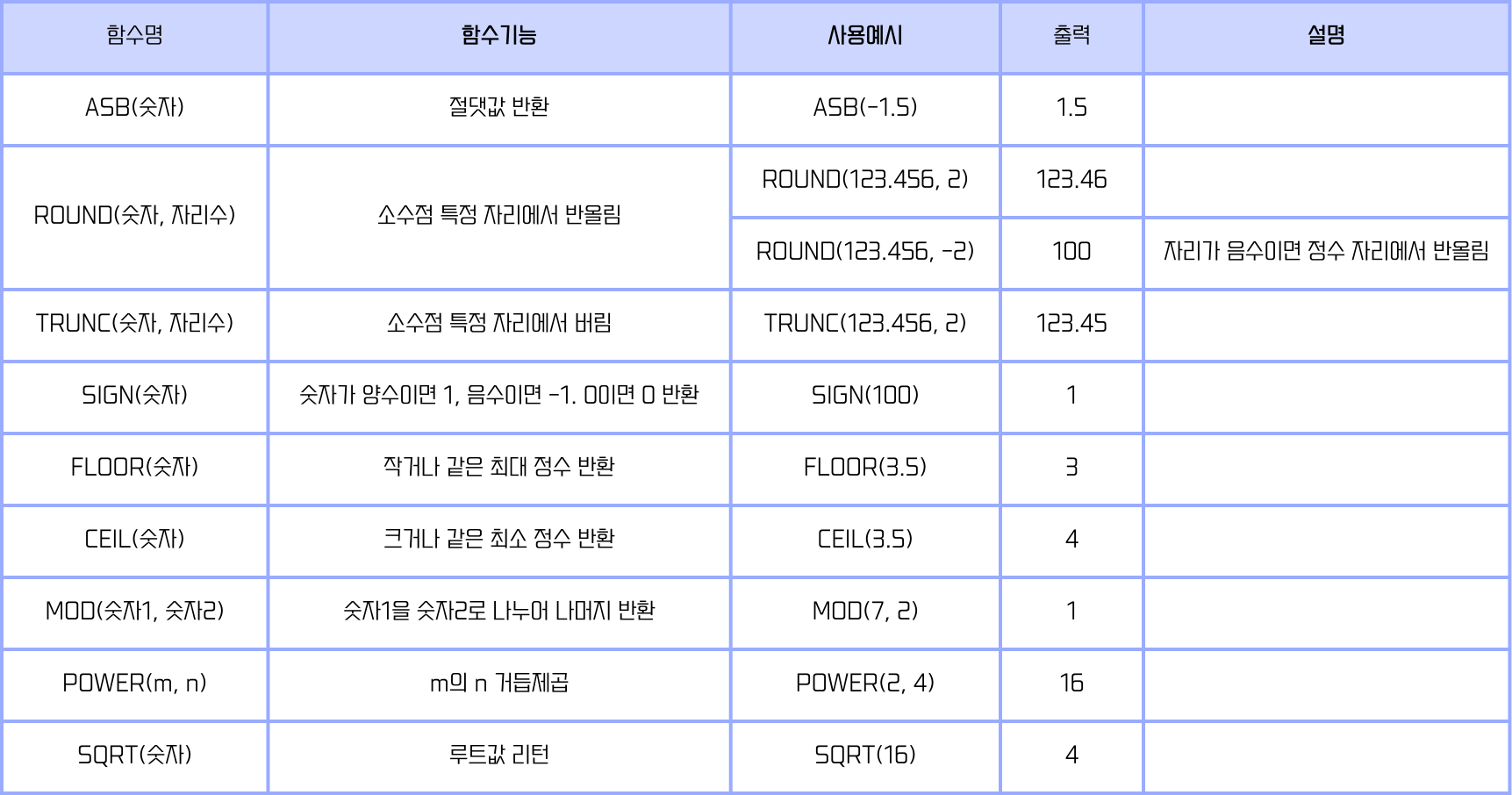
- 숫자형 함수
- 숫자를 입력하면 숫자 값을 반환한다.
- 단일행 함수 형태이다.
- ORACLE과 SQL Server끼리 함수가 거의 동일하다.
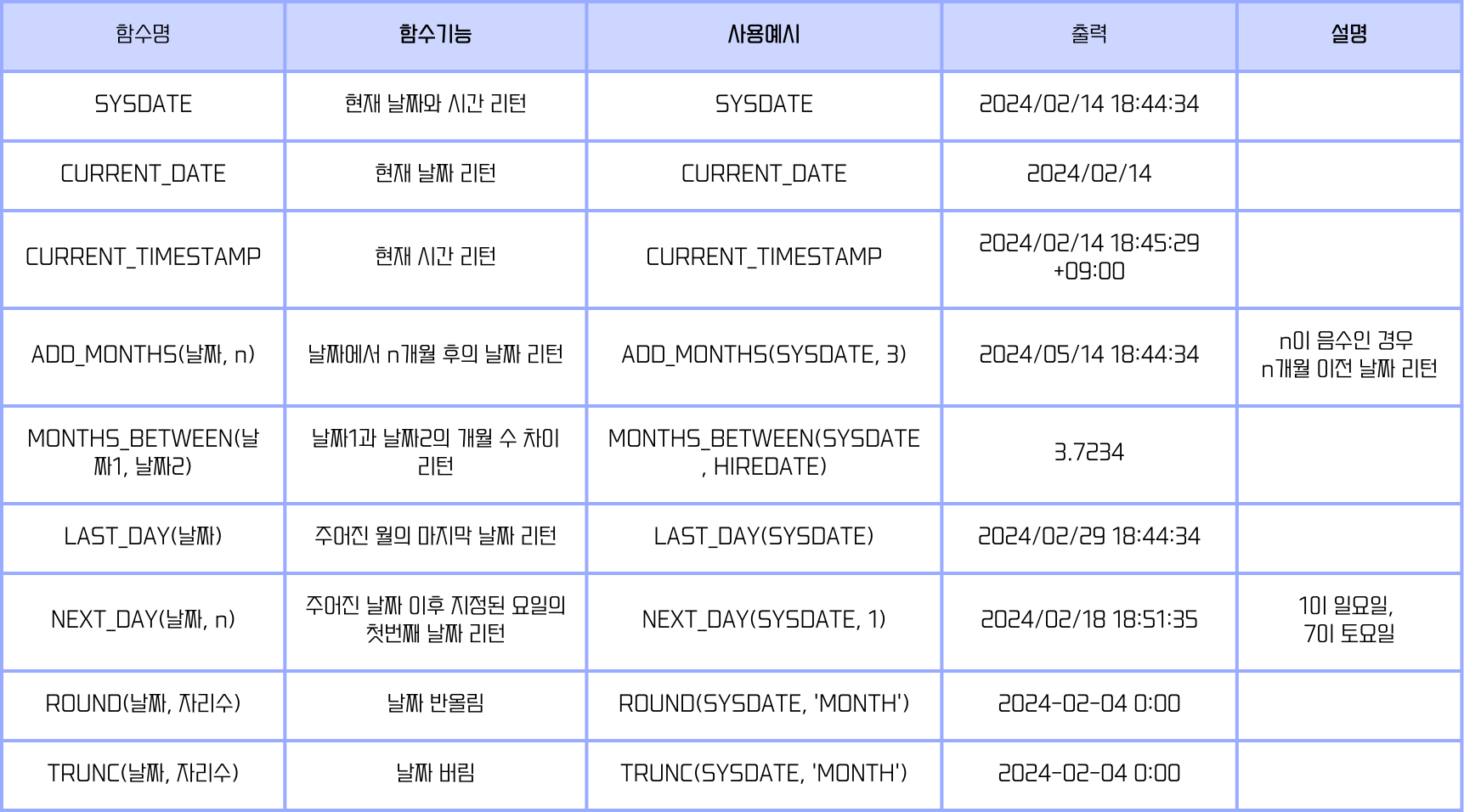
- 날짜형 함수
- 날짜와 연산과 관련된 함수이다.
- ORACLE과 SQL Server끼리의 함수가 거의 다르다.
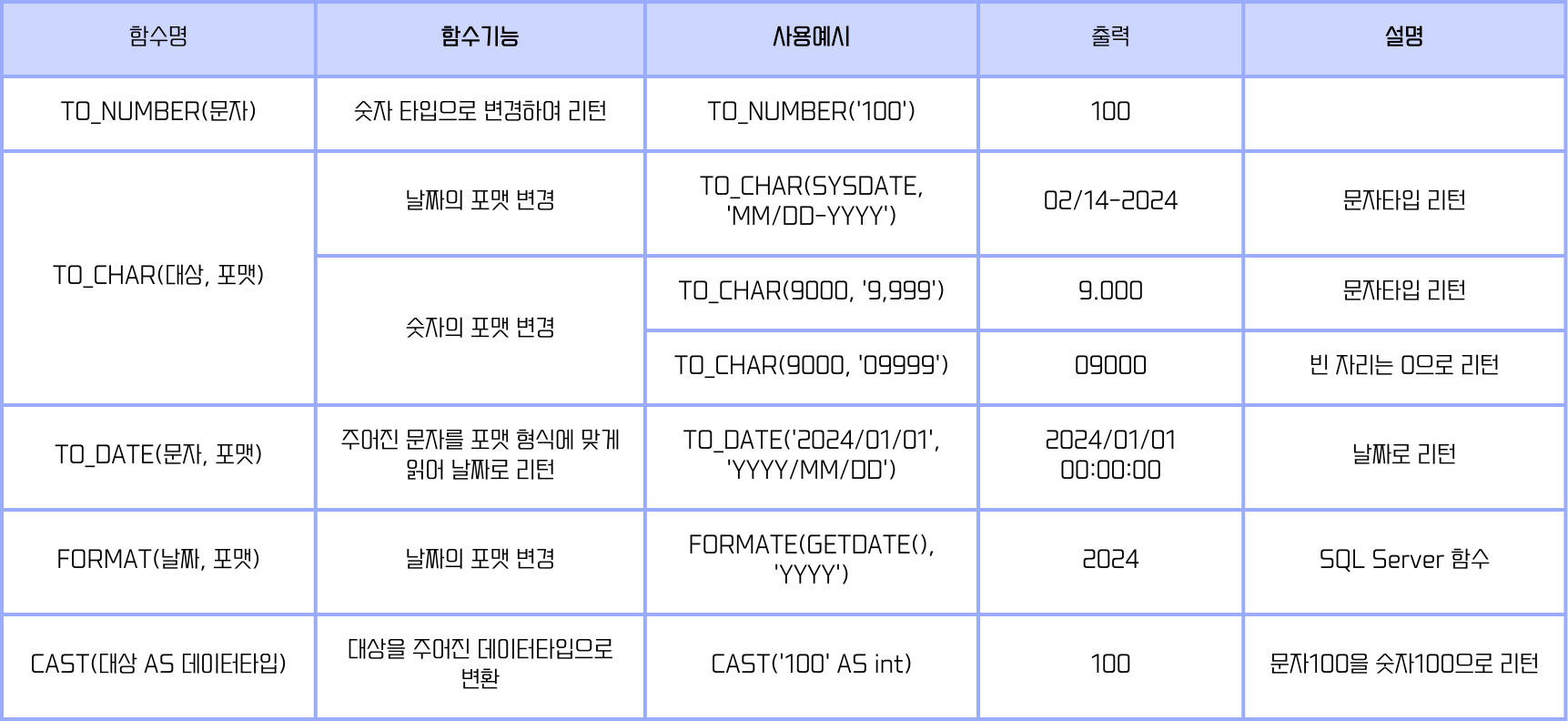
- 변환 함수
- 값의 데이터 타입을 변환한다.
- 문자를 숫자로, 숫자를 문자로, 날짜를 문자로 변경한다.
- 그룹함수
- 다중행 함수이다.
- 여러 값이 input 값으로 들어가서 하나의 요약된 값이 리턴된다.
- GROUP BY와 함께 자주 사용된다.
- ORACLE, MYSQL Server끼리 함수가 거의 동일하다.

- 일반함수
#CASE문 사용 예제
SELECT DEPTNO CASE DEPTNO WHEN 10 THEN '인사부'
WHEN 20 THEN '총무부'
WHEN 30 THEN '재무부'
ELSE '기타'
END AS DNAME1,
CASE WHEN DEPTNO = 10 THEN '인사부'
WHEN DEPTNO = 20 THEN '총무부'
WHEN DEPTNO = 30 THEN '재무부'
ELSE '기타'
END AS DNAME2
FROM EMP;
조인(JOIN)
- 여러 테이블의 데이터를 사용하여 동시 출력하거나 참조할 경우에 사용
- FROM절에 조인할 테이블을 내열하면 된다.
- ORACLE 표준은 테이블 나열 순서가 중요하지 않지만 ANSI 표준은 OUTER JOIN 시 순서가 중요하다.
- WHERE절에 조인 조건을 작성한다.
- 동일한 열 일므이 여러 테이블에 존재할 경우 열 이름 앞에 테이블 이름 또는 별칭을 붙인다.
- N개의 테이블을 조인하려면 최소 N-1개의 조인 조건이 필요하다.
조인 종류
조건의 형태에 따라
- EQUI JOIN : JOIN 조건이 동등 조건인 경우
- NOT EQUI JOIN : JOIN 조건이 동등 조건이 아닌 경우
- 조인 컬럼의 비교 조건이 <, BETWEEN A AND B와 같이 = 조건이 아닌 연산자를 사용하는 경우
조인 결과에 따라
- INNER JOIN : JOIN 조건에 성립하는 데이터만 출력하는 경우
- OUTER JOIN : JOIN 조건에 성립하지 않는 데이터도 출력하는 경우
- LEFT, RIGHT, FULL OUTER JOIN으로 나뉜다.
- NATURAL JOIN : 조인조건 생략 시 두테이블에 같은 이름으로 자연 연결되는 조인
- CROSS JOIN : 조인조건 생략 시 두 테이블의 발생 가능한 모든 행을 출력하는 조인
- SELF JOIN : 하나의 테이블을 두 번 이상 참조하여 연결하는 조인
EQUI JOIN
- JOIN 조건이 = 비교를 통해 같은 값을 가지는 행을 연결하여 결과를 얻는 조인 방법
- SQL에서 가장 많이 사용하는 조인 방법
- WHERE절에 두 테이블의 공통 칼럼에 대한 조인 조건을 나열
SELECT 테이블1.컬럼, 테이블2.컬럼
FROM 테이블1, 테이블2
WHERE 테이블1.컬럼 = 테이블2.컬럼;
SELF JOIN
- 한 테이블 내의 각 행끼리 관계를 갖는 경우의 조인 기법
- 한 테이블을 참조할 때마다 명시해야 한다.
- 테이블명이 중복되므로 반드시 테이블 별칭을 사용해야 한다.
EMPLOYEES 테이블에거 각 직원의 이름과 매니저의 이름을 함께 출력하려고 한다.

SELECT E1.EMPLOYEE_ID, E1.FIRST_NAME, E1.LAST_NAME, E1.MANAGER_ID, 32.EMPLOYEE_ID, E2.FIRST_NAME, E2.LAST_NAME
FORM EMPLOYEES E1, EMPLOYEES 31
WHERE E1.MANAGER_ID=E2.EMPLOYEE_ID;
INNER JOIN
- 조인 조건이 일치하는 행만 추출한다.
- ORACLE에서의 기본 조인으로 별도의 문법이 존재하지 않고 WHERE절에 조인 조건을 나열하면 된다.
- ANSI 표준의 경우 FROM절에 INNER JOIN 혹은 JOIN을 명시해야 하며 USING이나 ON 조건절을 필수적으로 사용해야 한다.
ON절
- 조인할 양 컬럼의 컬럼명이 서로 다르더라도 사용이 가능하다.
- ON 조건의 괄호는 생략 가능하다.
- 컬럼명이 같을 경우에는 테이블 이름이나 별칭을 사용해야 하낟.
- ON 조건절에서는 조인 조건을 명시해야 하고, WHERE절에서는 일반 보건을 명시해야 한다.
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 INNER JOIN 테이블2
ON 테이블1.조인컬럼=테이블2.조인컬럼;USING절
- 조인할 컬럼명이 같을 경우 사용한다.
- 괄호가 필수이며 별칭이나 테이블 이름 같은 접두사를 붙일 수 없다.
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 INNER JOIN 테이블2
USING (동일컬럼명);NATURAL JOIN
- 두 테이블 간의 동일한 이름을 가지는 모든 컬럼에 대해 EQUI JOIN을 수행한다.
- USING, ON, WHERE절에서 조건을 정의할 수 없다.
- JOIN에 사용된 컬럼들은 데이터 유형이 동일해야 한다.
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 NATURAL JOIN 테이블2;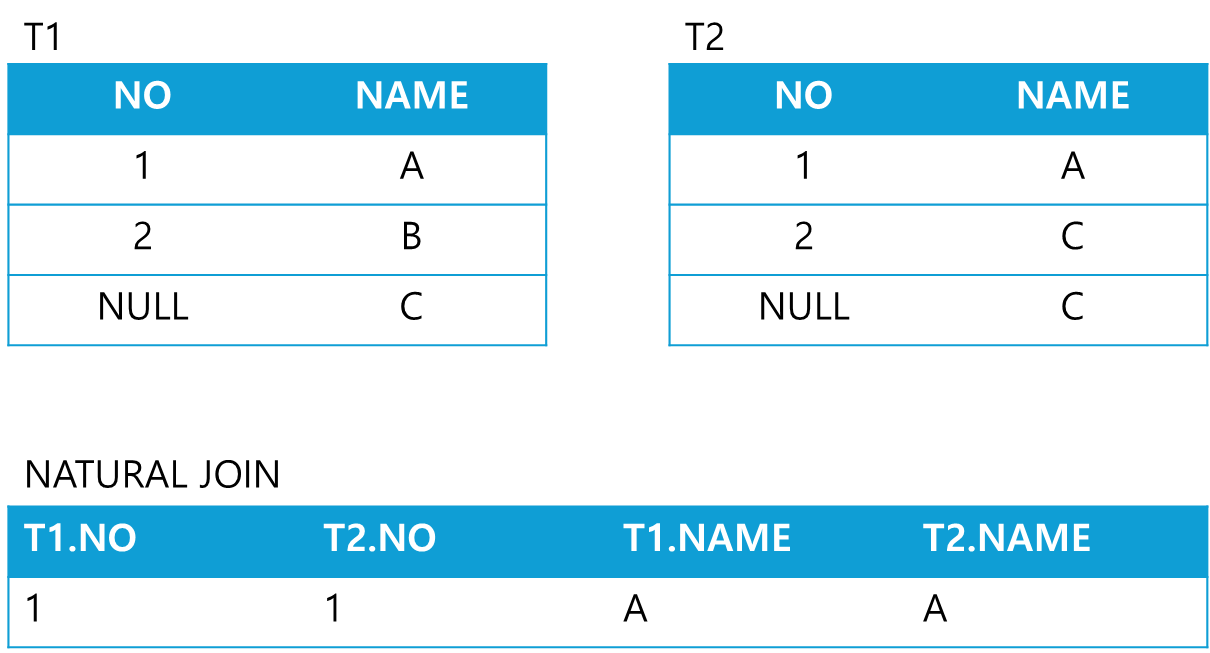
CROSS JOIN
- JOIN 조건이 없는 경우 생성 가능한 모든 데이터들의 조합
- 카타시안 곲을 출력한다.
- 양쪽 테이블 행의 수의 곱한 수의 데이터 조합이 발생한다.
##ANSI
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1 CROSS JOIN 테이블2;
##ORACLE
SELECT 테이블1.컬럼명, 테이블2.컬럼명
FROM 테이블1, 테이블2;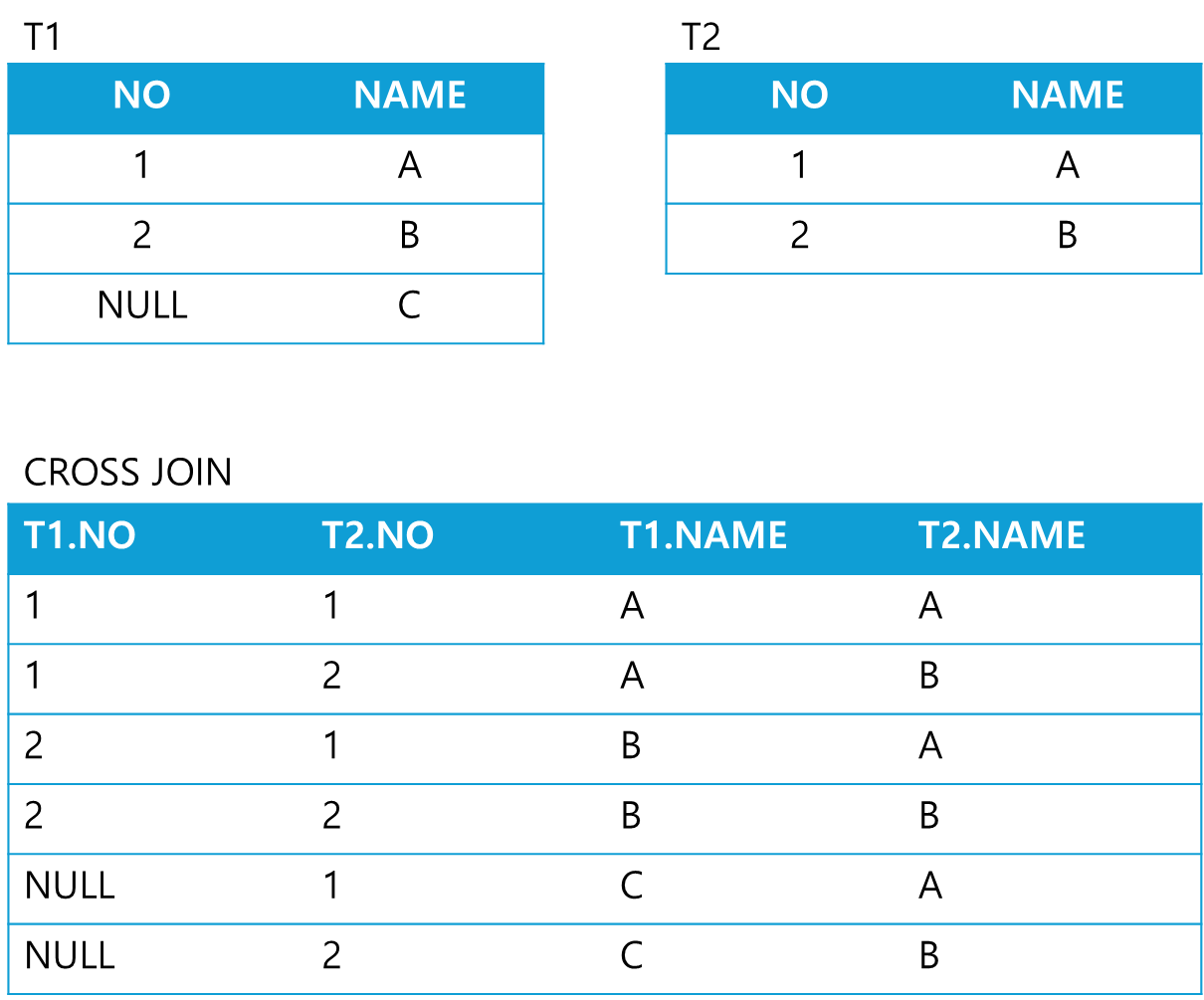
OUTER JOIN
- JOIN 조건에서 동일한 값이 없는 행도 반환할 때 사용
- 두 테이블 중 한 쪽이 NULL을 가지면 EQUI JOIN 시에 출력되지 않는데 이를 출력하고자 할 때 OUTER JOIN을 사용한다.
- 테이블 기준 방향에 따라 LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN으로 구분도니다.
- OUTER은 생략 가능하다.
LEFT OUTER JOIN
FROM절에서 나열된 왼쪽 테이블에 해당하는 데이터를 읽은 후 우측 테이블에서 JOIN 대상을 읽어온다. 즉, 왼쪽 테이블이 기준이 되어 오른쪽 테이블 데이터를 채우는 것이다. 우측에서 같은 값이 없는 경우에는 NULL이 출력된다.
RIGHT OUTER JOIN
오른쪽 테이블이 기준이 되어 오니쪽 테이블 데이터를 채우는 방식이다. FROM절에서 테이블 순서를 변경하면 LEFT OUTER JOIN으로 수행이 가능하다.
FULL OUTER JOIN
두 테이블 전체를 기준으로 결과를 생성하여 중복 데이터는 삭제 후에 리턴한다.
'IT > SQLD' 카테고리의 다른 글
| [SQLD/IT자격증] SQLD 2과목 "관리구문" 이론 정리 (0) | 2024.08.18 |
|---|---|
| [SQLD/IT자격증] SQLD 2과목 "SQL 활용" 이론 정리 (1) | 2024.08.18 |
| [SQLD/IT자격증] SQLD 1과목 "데이터모델링의 이해" 이론 정리 (0) | 2024.08.13 |