![[개념] Elastic NLP](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcrQzEz%2FbtsCZjtMvqL%2FF2hmIueilnpOdOJrW07ZqK%2Fimg.png)
NLP의 개념
(1) NLP가 하는 일
- Low level parsing
- Tokenization : 문장 분리
- stemming : 어근 추출
- Word and phrase level
- NER : 고유 명사 인식
- POS tagging : 형태소 분석
- noun phrase chunking : 명사구 단위 분리
- dependency parsing : 의존 구조 분석
- coreference resolution : 참조 관계 분석
- Sentence level
- sentiment analysis : 감정 분석
- machine transiation : 기계 번역
- Multi sentence and paragraph level
- entailment predinction : 모순 관계 예측
- question answering : 질의 응답
- dialog systems : 대화형 챗봇
- summarization : 전문 요약
(2) 단어 학습이 이루어지는 과정 (Word Embedding)
1. BoW (Bag of Words)
많이 나오는 단어들을 통해 추론하는 기법이다. 특히 고유 어휘 단어를 중점으로 본다. 그러나 이 경우에는 불확실할 수 있으므로 기계가 이해할 수 있게 단어를 벡터로 만드는 작업으로 발전했다.
단어를 벡터로 만들어 문장을 벡터의 합으로 표현하는 기법인 One-hot vector가 등장했다. 단어별로 고유 벡터를 정하고 아래와 같이 문장 구별을 할 수 있도록 하는 기법이다.
Sentece 1 : "John really really loves this movie"
→ John + really + really + loves + this + movie [ 1 2 1 1 1 0 0 0 ]
그러나 이 경우에는 차원이 늘어나 비용 문제가 발생하게 된다.
2. Word2Vec
단어의 유사도를 거리로 표현하는, 비슷하거나 같은 관계의 단어는 비슷한 Vector을 가진다는 기법이다. 거리와 방향으로 표현되는 vector로 단어 사이의 관계를 나타냄으로써 기계가 이해 가능하도록 한다.
Vector로 표기하는 unique word를 표기하는 One-Hot Representation과 가능성을 분산 표기하는 Distributed Representation 기법이 있다.
거리가 가까울수록 두 단어가 유사하다고 보고, 방향이 비슷할수록 단어 간의 관계가 유사하다고 본다. 아래와 같이 나타난다.
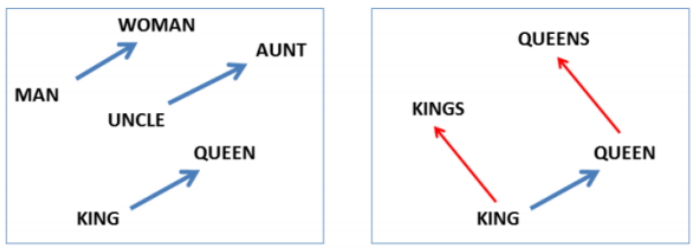
아래 링크에서 직접 확인해볼 수 있다. wevi (ronxin.github.io)
wevi
Training data (context|target): Presets: Update and Restart Update Learning Rate Next 20 100 500 PCA
ronxin.github.io
위 링크에서 presets를 선택하고 초록색 버튼들에서 학습할 횟수를 선택하면 아래와 같이 모델이 학습된다.
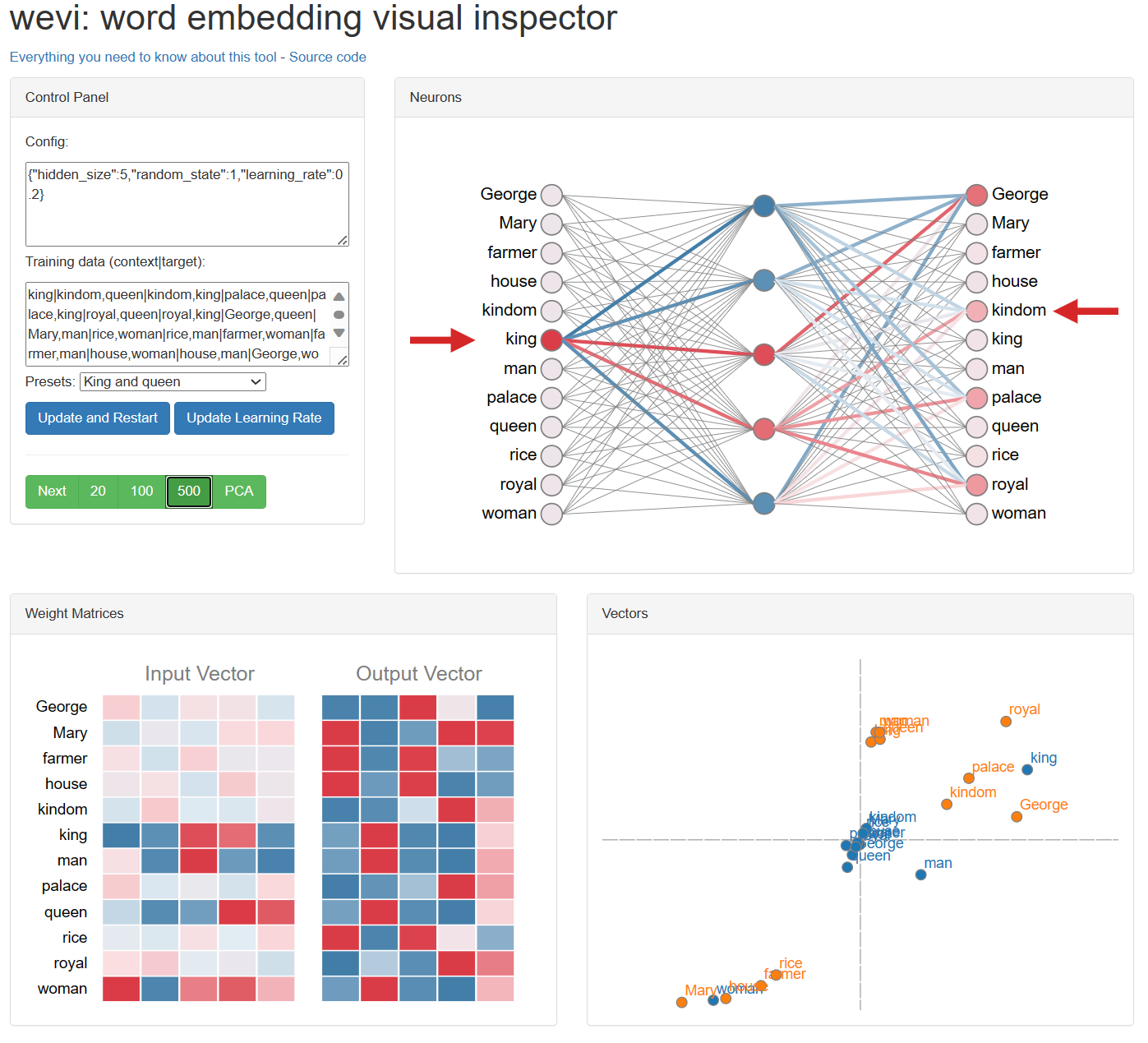
Word2Vec은 여러 가지로 활용이 가능한 기법이다.
Word2Vec은 발전시켜 같은 원리로 자연어 번역도 유추할 수 있다. 단어 간의 위치, 관계가 모든 나라에서 비슷하게 나타나기 때문이다.

Word2Vec은 image captioning에도 활용할 수 있다. 이미지를 설명할 수 있는 기능인데 이미지에 맞는 단어를 추출하여 표현한다.
마지막으로 우리말로도 Word2Vec 적용이 가능한데 아래 링크에서 가능하다.
Korean Word2Vec
ABOUT 이곳은 단어의 효율적인 의미 추정 기법(Word2Vec 알고리즘)을 우리말에 적용해 본 실험 공간입니다. Word2Vec 알고리즘은 인공 신경망을 생성해 각각의 한국어 형태소를 1,000차원의 벡터 스페이
word2vec.kr
아래 예시는 한국과 서울의 관계는 도쿄와 어떤 것의 관계와 같은지 모델에게 묻는 예제이다.

그래서 Word2Vec은 같은 분류가 아닌 단어를 식별할 수 있다.
한편 Word2Vec은 단어 사이의 문맥적인 관계에 취약하기 때문에 다른 해결방법이 등장한다.
Elasticsearch NLP
Text matching (전통적인 검색 방법)
찾으려는 검색어가 실제 포함된 document를 찾는다. 주로 단어 단위로 찾고 많은 단어가 포함될수록 적합 점수가 높다. 따라서 찾으려는 검색어와 같이 검색될 단어를 미리 사전에 추가해두어야 한다.
Vector Similarity
1. NLP를 도입한 검색 방법
단어와 문장을 Vector로 인코딩하는 기법으로 텍스트뿐만 아니라 음성으로도 검색이 가능하게 되었다.
2. Brute force
Elasticsearch version 7.3에 있었던 기법으로 무차별 대입 검색을 하는 방법이다. 시공간적 제약이 없어야 가능하며 효율적이라고 보기에는 어려운 기법이다.
따라서 Elasticsearch에 있어서는 상위 결과를 다시 랭키하거나 필터링하기에 용이하다. 그러나 필드와 레이어가 늘어나면 연산이 선형적으로 증가하여 대용량 인덱스 연산에 불리하다는 단점이 있다.
3. HNSW & KNN
version 8.* 에 있었던 기법이다. Greedy를 기본으로 하는 기법으로 내 위치를 기준으로 가장 가까운 쿼리, 결과를 보여준다.
필드와 레이어가 늘어나면 연산이 logN으로 증가하여 대용량 인덱스 연산에 유리하다는 장점이 있지만, 대용량 처리를 위해 약간의 정확도를 포기해야 한다는 단점이 있다.
4. Brute force + HNSW
두 가지를 합쳐 사용하며 전략적으로 두 검색 기능 중 율한 것을 찾아 자동 선택하는 기법이다.
① 필터에 포함된 도큐먼트의 개수를 찾는다.
② HNSW로 그래프 순회를 시작한다 .모든 노드를 순회하지만 인덱스를 통과하는 노드만 수집한다.
③ 평가된 노드 수가 필터를 통과한 노드 수를 초과하면 필터를 통과한 도큐먼트에 대해 Brute force를 실행한다.
Vector Search
Elasticsearch는 검색 대상 필드를 Vector로 치환하여 검색한다. 이후 최근접 벡터를 검색 대상으로 선정한다.
아래 블로그에서 그 과정을 확인할 수 있다.
'Cloud > ElasticSearch' 카테고리의 다른 글
| [실습] Elasticsearch NLP - Sentiment Analysis 하기 (0) | 2024.01.02 |
|---|---|
| [실습] Elasticsearch NLP - Text Embedding과 KNN search 하기 (0) | 2024.01.02 |
| [실습] Elasticsearch에서 Machine Learning 사용하기 (0) | 2023.12.29 |
| [개념] Elasticsearch에서의 Machine Learning (0) | 2023.12.29 |
| [실습] Elasticsearch Query 사용하기 (0) | 2023.12.29 |