![[실습] Elasticsearch에서 Machine Learning 사용하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FFiTe7%2FbtsCJjbDUXT%2Fs6p8h91o65CC8Y64lBqlhK%2Fimg.png)
실습 개요
- Elasticsearch가 제공하는 machine learning 기능을 사용해본다.
- 목록
- Anomaly Detection
- Population Detection
- Outlier Detection
- supervised learning & prediction
1. 시계열 데이터에서 Single Metric으로 이상징후 탐지하기 & forecating하기
(1) Machine Learning > Anomaly Detection > Create job 에 접근한다.
job은 머신러닝 모델을 의미한다.
(2) 데이터셋 선택 > Single metric 선택 > Use full data 클릭한다.
이번 실습에서는 single metric을 선택한다.
(3) field를 선택한다.
y축을 선택하는 것이다. 본 포스팅에서는 구매건수에 대해 선택하겠다. y축을 선택하는 것은 항상 매우 중요하다.
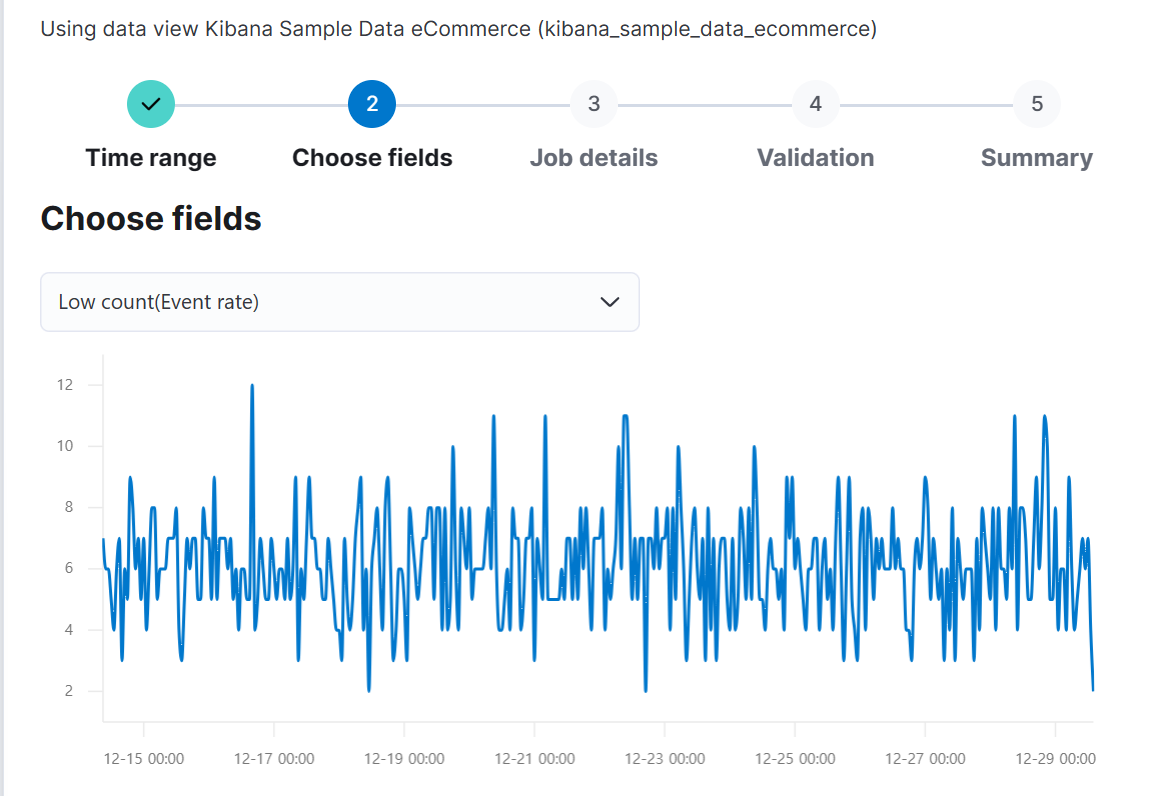
구매건수가 떨어지는 시점만 잡는 이상징후 탐지가 된다.
(4) Bucket span을 설정한다.
x축을 1시간마다 bucket으로 묶는다.
(5) Job ID와 Groups를 임의로 설정한다.
Groups는 태그와 같은 역할을 한다.
(6) Create job을 클릭하면 바로 학습하기 시작한다.
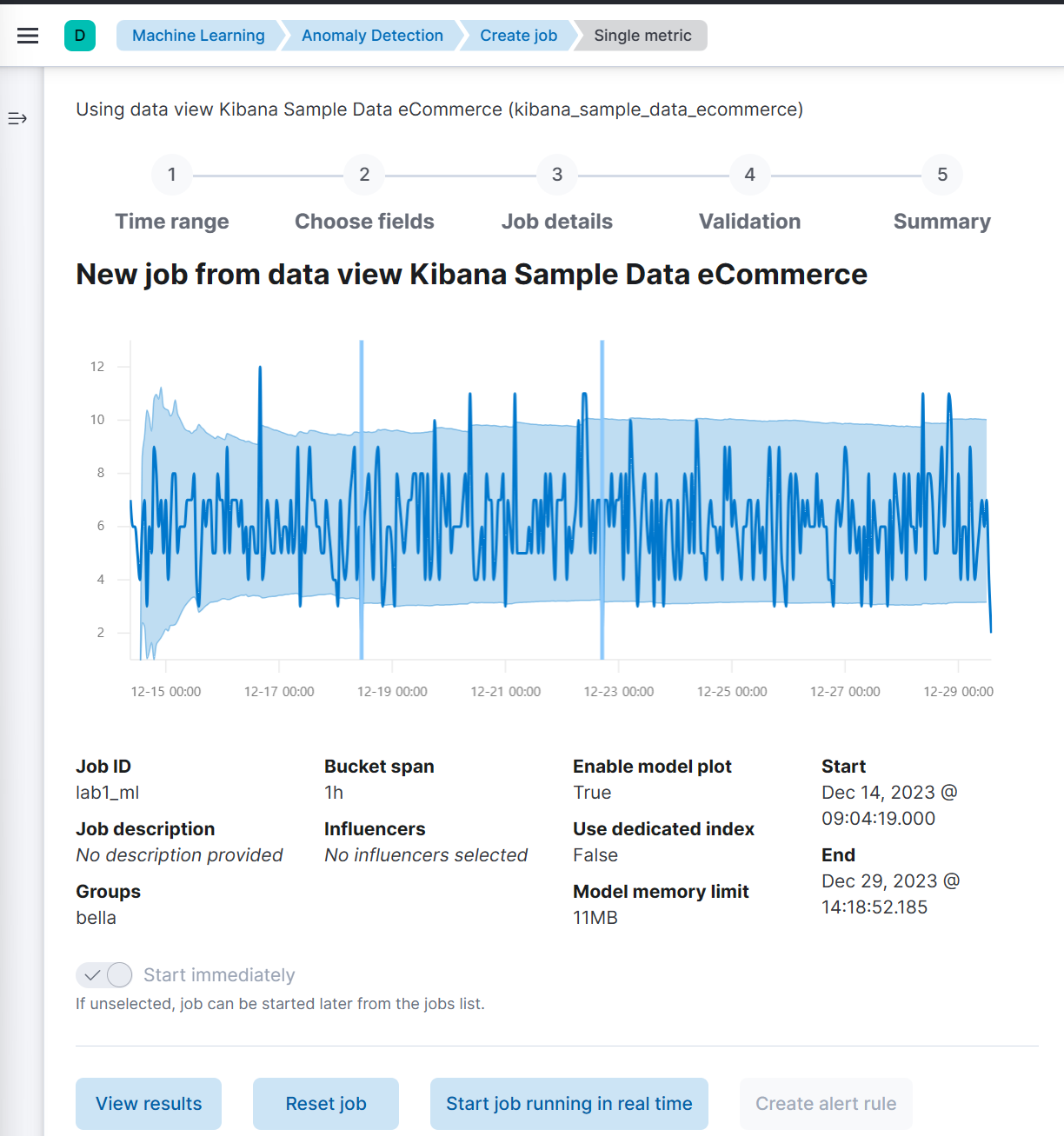
(7) Jobs에서 방금 만든 내용을 확인한 후 anomaly explorer을 확인한다. (달력모양 아이콘)


칸에 색이 없으면 이상징후가 없는 것이고 색이 있으면 이상징후가 있던 것이다.
그 정도는 위에 0~100 사이이다. 100에 가까울수록 더욱 이상한 것이다.
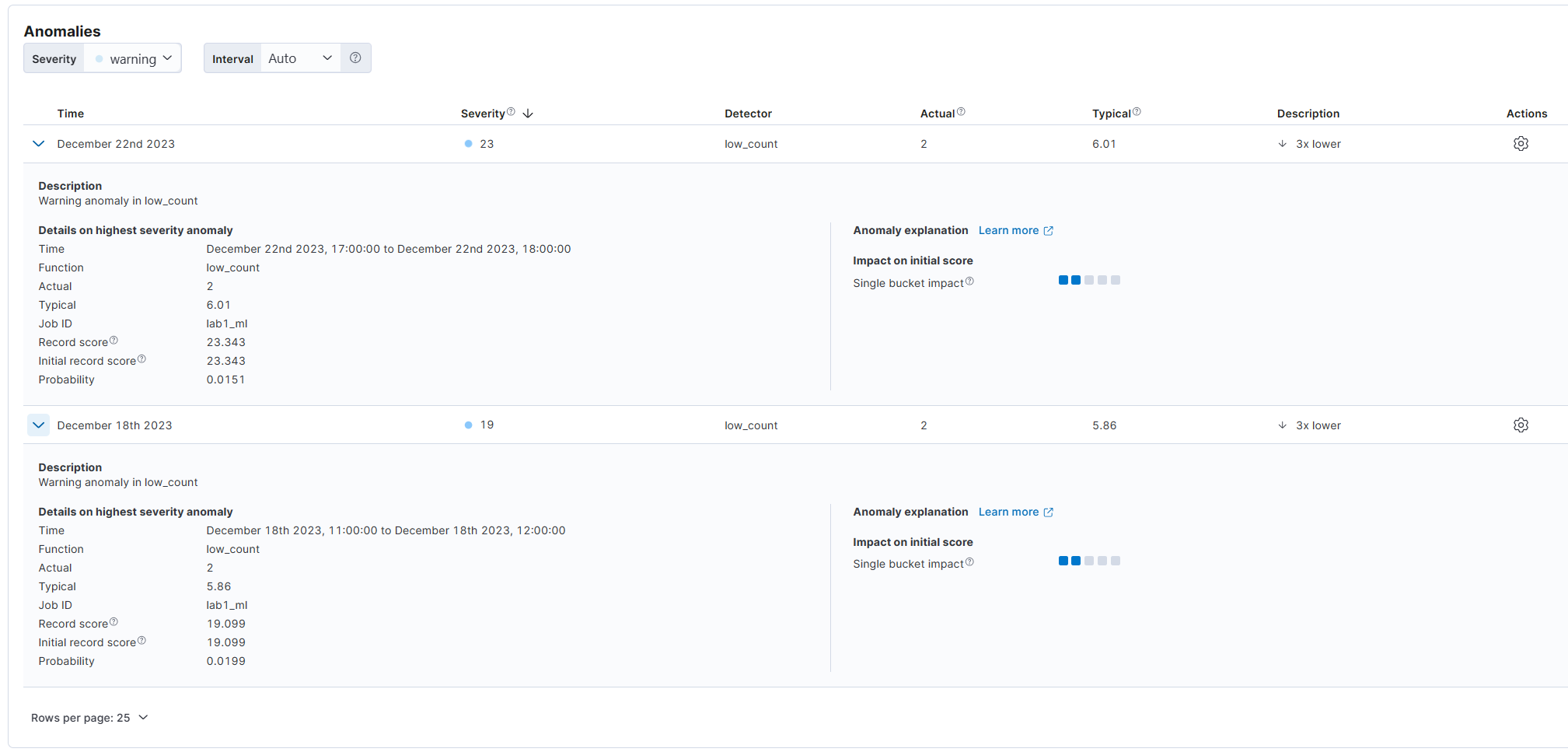
이 내용을 통해 얼마나 이상한지 수치로 확인할 수 있고 점점 데이터가 누적되면 어느 정도 이상수치는 무시하는 것으로 타협할 수도 있다.
Typical에 이상적인 수치를 알려주고 Actual에 실제 이상 수치를 알려준다.
(8) Single Metric Viwer을 통해 그래프를 통해 이상징후도 탐지할 수 있다.
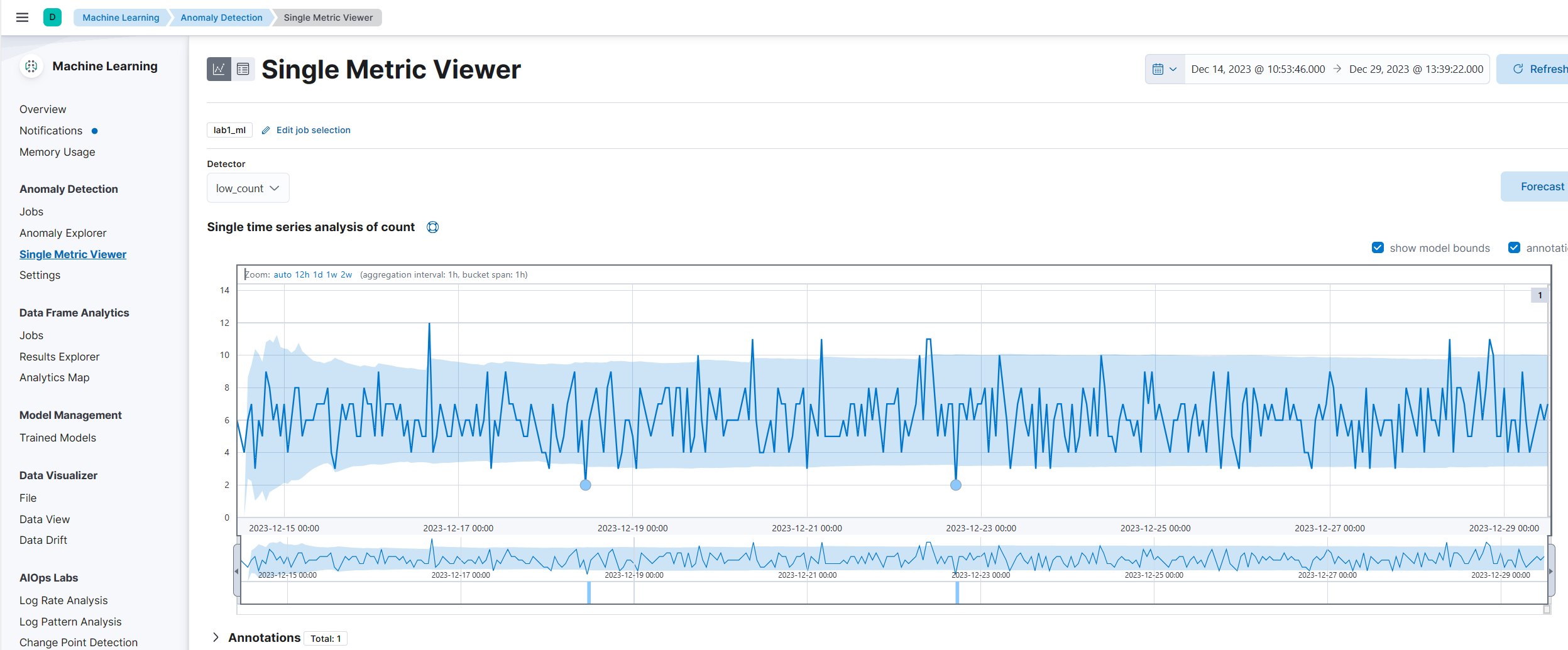
이런 내용들을 알람이 오게 설정하여 항상 모니터링 하지 않아도 이상징후를 확인할 수 있다. threshold로 alerting하는 것보다는 server마다 다르게 값을 설정하는 것이 더 효율적이라고 볼 수도 있다.
(9) Forecast 버튼을 클릭한다.
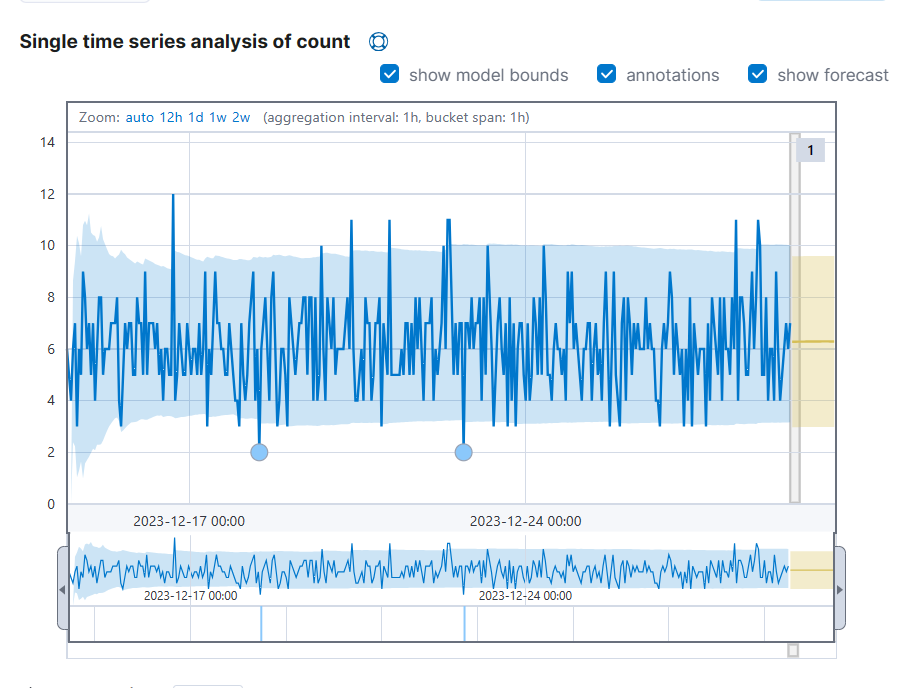
내일 어떨지 예측치를 한 번 볼 수도 있다.
+ y축 여러 개를 한 번에 학습하는 multi metric도 가능하다.
2. Population Analysis (특이한 점 찾기)
(1) Machine Learning > Anomaly Detection > Create job > 데이터셋 선택 > Population 선택 > Use full data 선택
(2) population field를 선택한다.
각 객체의 behavior을 보고 이상한 것을 찾아야 하기 때문에 custom의 이름으로 하였다.
(3) Add metric을 선택한다.
sum(taxful_total_price)를 선택해 유저별로 쓴 돈을 추적한다.
(4) Create job을 클릭한다.
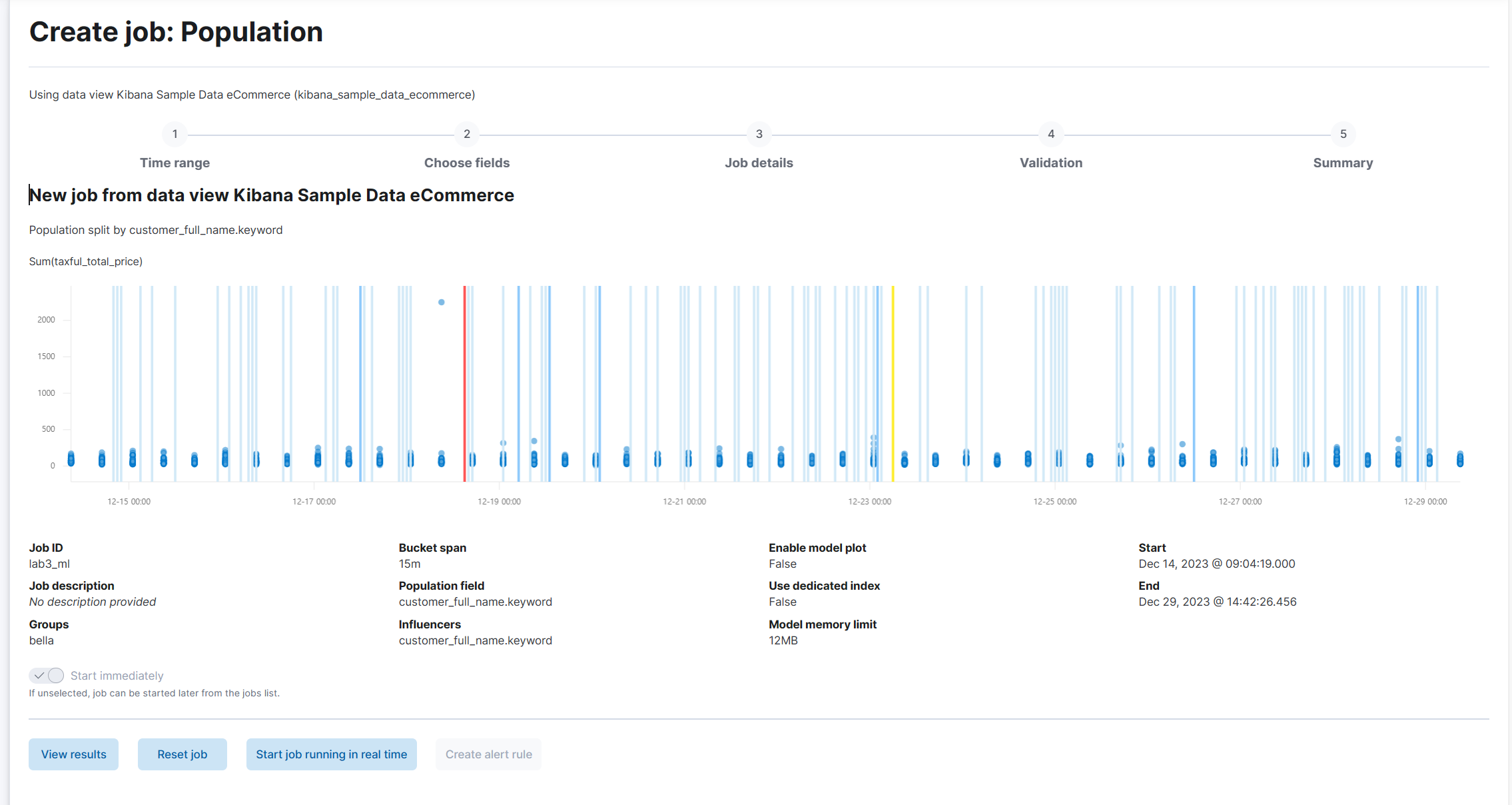
(5) View Results를 클릭한다.

사람별로 이상징후를 탐지한 것을 볼 수 있다.

이상징후 하나를 클릭하면 해당 내용을 확인할 수 있다. 확실히 하늘색 점이 다른 점들과 다른 양상을 보이는 것을 알 수 있다.
3. Data transform, Outlier Detection 하기
(1) Stack Management > Transforms > Create Transform > 데이터셋 선택 > User full data
(2) field 정하기 = Entity 정하기
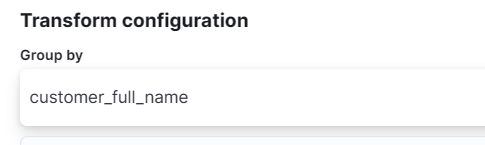
(3) Aggregation 정하기
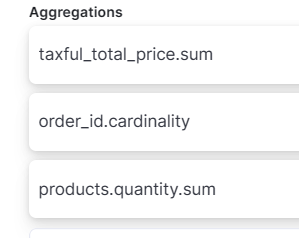
(4) 아래 Preview에서 생성될 field를 볼 수 있다.
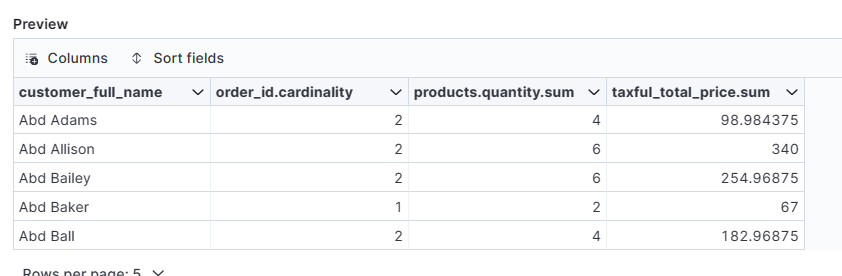
사람 하나 당 document 하나가 만들어질 것이다.
(5) Create and Start > Discover
(6) 결과를 확인할 수 있다.
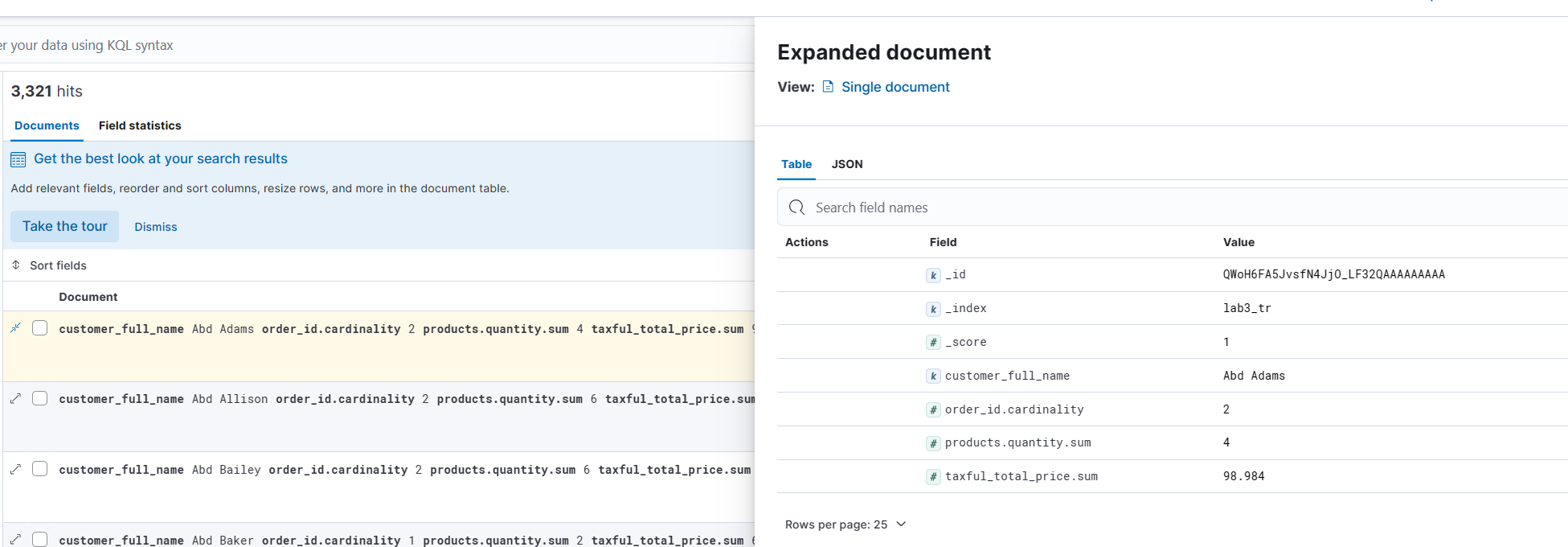
시간 정보가 없어서 비시계열 데이터이다.
한 사람이 얼마나 물건을
(7) Machine Learning > Data Frame Analytics > Create job > Outlier detection 선택 > Create

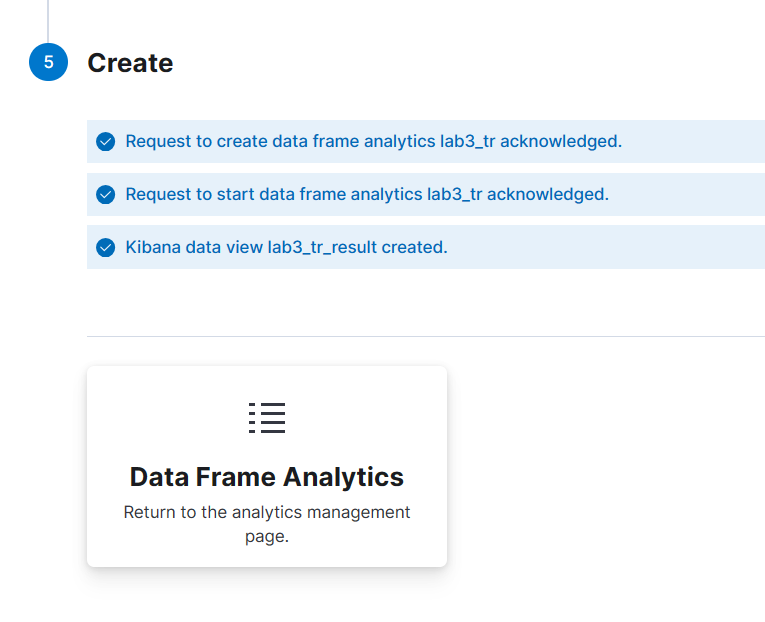
(8) Action의 View 선택
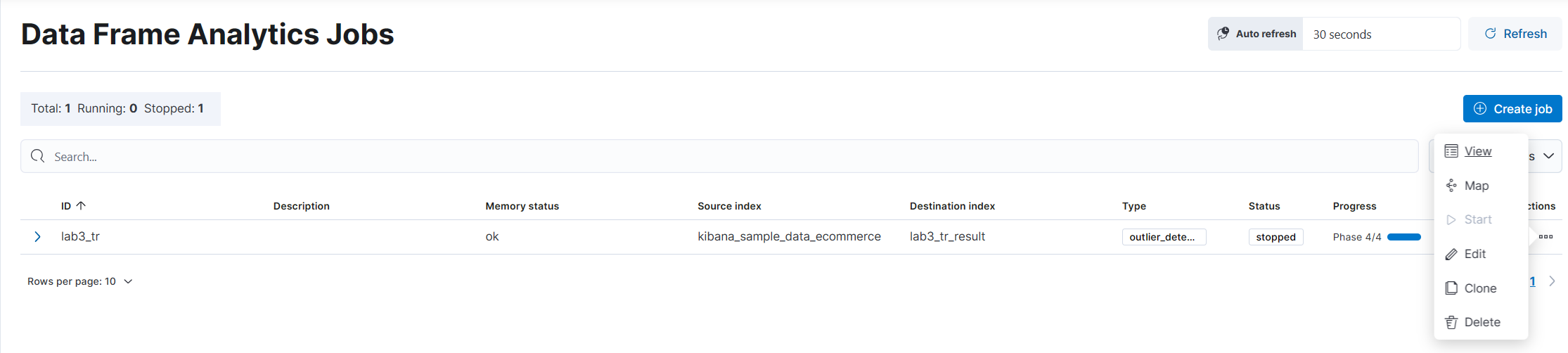
(9) 결과를 확인할 수 있다.

4. Supervised Learning, Classification 하기
두가지 데이터를 합쳐 유저가 우리 서비스를 떠날지 안떠날지를 확인한다.
(1) Machine Learning > File 에서 Data 를 올려 Index를 생성한다.
(2) Dev Tools에서 아래 코드를 실행한다.
PUT /_enrich/policy/customer_metadata
{
"match": {
"indices": "customers",
"match_field": "phone_number",
"enrich_fields": [
"account_length",
"churn",
"customer_service_calls",
"international_plan",
"number_vmail_messages",
"state",
"voice_mail_plan"
]
}
}
# Execute the policy so we can populate with the metadata
POST /_enrich/policy/customer_metadata/_execute
# Our enrichment pipeline for generating features
PUT _ingest/pipeline/customer_metadata
{
"description": "Adds metadata about customers by phone_number",
"processors": [
{
"enrich": {
"policy_name": "customer_metadata",
"field": "phone_number",
"target_field": "customer",
"max_matches": 1
}
}
]
}
#transform for enriching the data for training
PUT _transform/customer_churn_transform
{
"source": {
"index": [
"calls"
]
},
"dest": {
"index": "churn",
"pipeline": "customer_metadata"
},
"pivot": {
"group_by": {
"phone_number": {
"terms": {
"field": "phone_number"
}
}
},
"aggregations": {
"call_charges": {
"sum": {
"field": "call_charges"
}
},
"call_duration": {
"sum": {
"field": "call_duration"
}
},
"call_count": {
"value_count": {
"field": "dialled_number"
}
}
}
}
}transform job까지 생성한다.
calls 데이터를 가져와 churn이라는 인덱스를 만들 것인데 phone_number로 grouping 할 것이다. phone_number 하나로 pitcher을 뽑을 것이다. 그럼 이제 전화를 했을 때 몇 개의 dial number가 있었는지 확인할 수 있다.
(3) Discover 메뉴에서 방금 만든 데이터셋이 접근한다.
(4) create data view를 한다.
방금 만든 index에 대해 create를 해준다.

(5) Machine Learning > Data Frame Analytics > Create Job에서 다음과 같이 설정한다.
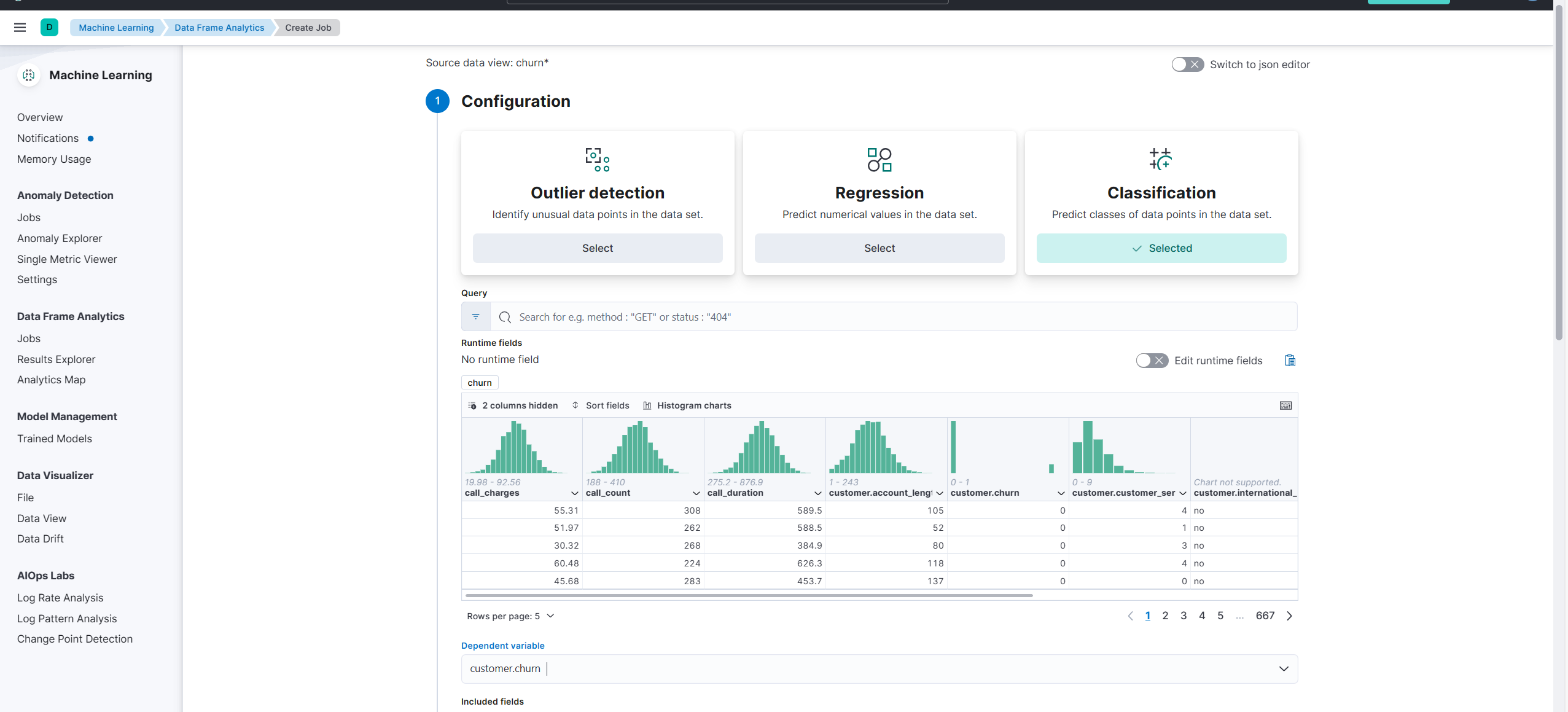
Classification을 선택하고 variable을 선택한다.

그리고 Incluede fields를 판단하여 제외 혹은 포함한다.

Training percent는 데이터셋의 몇 퍼센트를 학습할 용도로 사용할지를 결정한다.
(6) Maching Learning > Data Frame Analytics > Results Explorer 에 접속하면 만든 모델을 볼 수 있다.
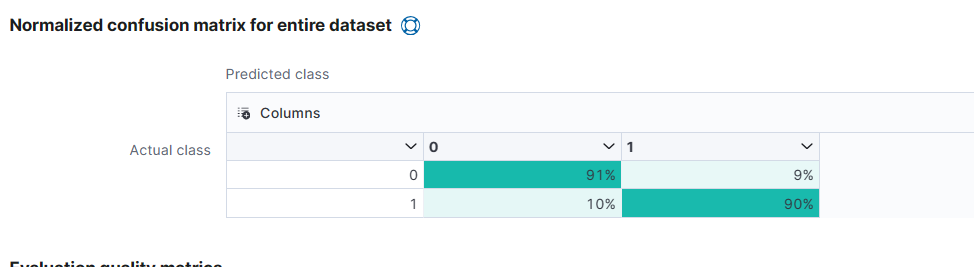
False positive 등에 대한 정보를 확인할 수 있다. 93% 정도 정확하게 맞추었다.

ROC curve는 왼쪽 위에 붙어 있을수록 좋다.
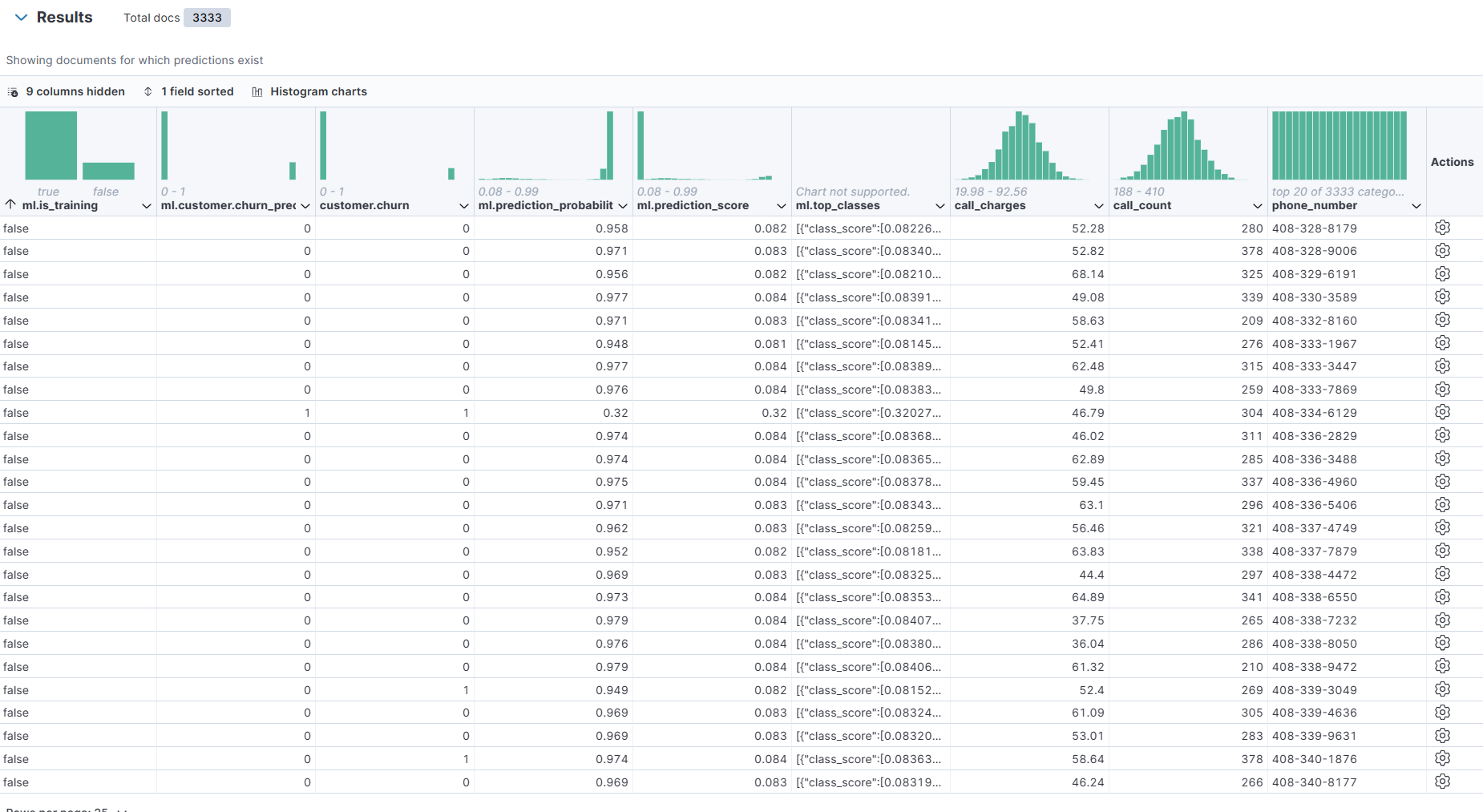
training하지 않은 데이터에 대해서 모델이 어떤식으로 output을 냈는지 볼 수 있다.
training을 false로 sort해주고 누구인지 알기 위해 phone number field를 추가해준다.
churn이 0이면 안 떠났다는 사실을 뜻하고, prediction은 그 사람이 떠났는지 안 떠났는지를 맞춘다.
(7) Dev Tools의 Console을 통해 방금 만든 모델을 확인할 수 있다.
GET _ml/inference/_stats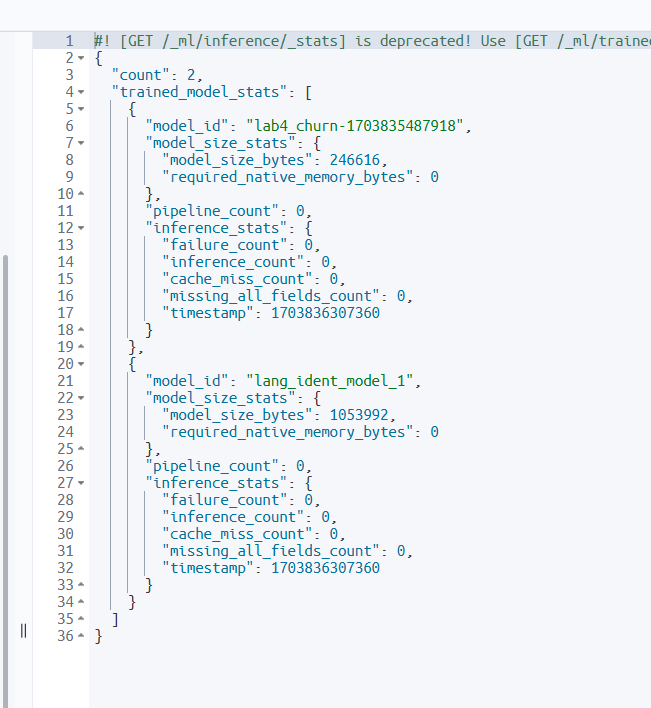
이 output에서 model_id까지 확인할 수 있다.
(8) 혹은 ingest pipeline을 거치게 할 수도 있다.
POST /_ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "본인의 모델 id",
"inference_config": {
"classification": {
"num_top_classes": 2
}
},
"field_map": {
"body": "text"
}
}
}
]
},
"docs": [
{
"_source": {
"customer.voice_mail_plan": "yes",
"call_count": 312,
"customer.number_vmail_messages": 15,
"customer.account_length": 119,
"customer.phone_number": "415-352-5118",
"customer.international_plan": "no",
"customer.state": "NM",
"call_charges": 46.7100000000003,
"customer.customer_service_calls": 5
}
}
]
"ml" 필드를 통해 document가 model을 통과한 결과를 확인할 수 있다. "customer.churn_prediction"을 통해 모델의 예측을 볼 수 있고 "prediction_score"을 통해 모델의 정확도를 확인할 수 있다.
'Cloud > ElasticSearch' 카테고리의 다른 글
| [실습] Elasticsearch NLP - Text Embedding과 KNN search 하기 (0) | 2024.01.02 |
|---|---|
| [개념] Elastic NLP (0) | 2024.01.02 |
| [개념] Elasticsearch에서의 Machine Learning (0) | 2023.12.29 |
| [실습] Elasticsearch Query 사용하기 (0) | 2023.12.29 |
| [개념] Elasticsearch Query (Query DSL, Aggregation) (0) | 2023.12.29 |