![[이론] ElasticSearch 개념, 특징, 기능](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FoaTBq%2FbtsCG2godJy%2FBa7JHRsNpOVBSkYDnEU5p0%2Fimg.png)
학교 SW중심대학사업단 X AWS AWS Cloud Winter Camp 오프라인 교육 첫날이 시작됐다! 5일 동안의 오프라인 첫날, ElasticSearch에 대한 기초적인 것을 배웠다.
1. Elasticsearch 소개
Elasticsearch는 오픈소스 검색 엔진으로 데이터의 가치를 높이기 위해 사용하는 부재료이다. 데이터를 적재하고 정제하여 클라이언트에게 보여주며 검색을 최적화하고 빠르게 하는 도구이다.
Elasticsearch는 여러 분야에서 검색 기능으로 활용이 되는데 아래와 같은 항목들에서 활용될 수 있다.
- 대외 서비스 활용 : 검색 포탈, 뉴스/지식백과/사전, SNS/e커머스/소셜서비스
- 대내 서비스 활용 : 사내포탈/그룹웨어, 개발소스/로그 통합검색, 업무/마케팅 자료분석
(1) RDB vs NoSQL
Elasticsearch와 RDBMS를 비교하기 전에 SQL과 NoSQL을 비교해보자.
| RDB (SQL) | NoSQL | |
| 데이터 저장 모델 | 테이블 | Json document, key-value 등 |
| 개발 목적 | 데이터 중복 감소 | 확장 가능성, 수정 가능성 |
| 예시 | Oracle, MySQL 등 | Elasticsearch, MongoDB |
| Schema | 엄격한 데이터 구조 | 유연한 데이터 구조 |
| 장점 | 데이터 구조를 보장한다. 데이터 중복 없이 한 번만 저장한다. |
유연하고 자유로운 데이터 구조를 가진다. 새로운 필드 추가가 자유롭다. 수평적 확장이 용이하다. |
| 단점 | 시스템 크기에 따라 query가 복잡하다. 비용이 큰 수직적 확장을 사용한다. |
명확한 데이터 구조를 보장하지 않는다. 데이터 중복이 가능하다. |
| 주로 사용되는 환경 | 데이터 구조가 명확한 경우 데이터 update가 잦은 시스템 |
데이터 구조가 명확하지 않은 경우 update가 자주 일어나지 않는 경우 |
(2) RDBMS vs ElasticSearch
- 기존 RDBMS의 한계
- 순방향 인덱스 방식으로 검색 속도가 상대적으로 느리다.
- 텍스트 매칭에 근거해서 데이터를 검색한다. (Ex.일치,포함)
- 데이터 시각화를 위한 WAS 개발 및 연동
- Elasticsearch의 대응 기술
- 역방향 인덱스 방식으로 검색 속도가 빠르다.
- n-gram 기반으로 Full-text 검색을 한다. (Ex.유의어,동의어,형태소 기반 자연어 처리 등)
- 자체 시각화 툴이 존재한다.
(3) Elastic 구성
- 데이터 수집 : 정형/비정형 데이터 수집
- “beat”라는 수집 기구가 한다. (Elastic의 Solution 중 하나)
- 데이터 전처리/인덱싱데이터 활용 : 분석 가능한 데이터로 인덱싱하여 저장
- "logstash"가 데이터를 전처리를 한다.
- 데이터 활용
- 데이터의 검색의 빠른 응답, 스코어 기반의 정확한 검색
- Elastic이 한다.
- 데이터의 시각화, 데이터 분석을 위한 대쉬보드
- Kibana가 한다.
- 데이터의 검색의 빠른 응답, 스코어 기반의 정확한 검색
- Elastic Stack : 비트, 로그 스태시, Elastic, Kibana
(4) Elastic 기능
- 검색
- 정형/비정형 빅데이터를 빠르고 정확하게 검색한다.
- 중앙집중식 데이터 저장소 플랫폼을 활용하여 통합관리로 원하는 데이터의 빠른 검색에 활용한다.
- 데이터 검색 시, 대소문자 구분, 띄어쓰기 구분, 형태소 분석, 사전 검색, 오탈자 보정, 불용어 검색, 자동 완성 등 다양한 검색이 가능하다.
- 식별/관측
- 대규모 로그, 메트릭 등 모든 이벤트를 모니터링한다.
- 다양한 장비의 운영 및 성능 관련 로그드을 수집하여 시각화 도구를 통한 모니터링 및 통계 분석에 활용한다.
- 보안
- 머신러닝 기반으로 보안 위협 예방, 탐지 및 대응, 알람과 조치까지 동작한다.
- 수집되는 로그 데이터의 비정상 패턴을 탐지하고 이상 탐지 시 알림 기능까지 한다.
- DW(DataWarehouse)
- 실시간으로 들어오는 로그를 수집하고 분석할 수 있는 시스템
- 다양한 Dimension과 Metric의 조합으로 Data Mart를 만들어 실시간 데이터를 다양한 용도로 활용한다.
(5) Elastic 기능 중 검색의 과정
- 수집이 안되는 형태는 없다.
- 데이터 (Source)
- 서버
- 데이터베이스
- 네트워크
- 보안
- 수집 형태
- API
- JSON
- SQL
- XML
- TXT
- LOG
- CSV
- FILE
- 정형/비정형 데이터를 수집한다.
- 데이터별 수집 주기/방식을 설정한다.
- Beat가 데이터를 수집한다.
- FILEBEAT
- METRICBEAT
- PAckETBEAT
- WINLOGBEAT
- 데이터 형태에 따라 쓰이는 BEAT가 다르다.
- Logstas가 수집이 끝나면 색인을 한다. (정제)
- 다양한 Plug-in을 제공한다.
- 실시간으로 데이터 색인이 가능하다. (색인 데이터를 순차적으로 실시간 반영한다.)
- Multi pipeline이 가능하다. (Kafka에 뒤쳐지지 않는다.)
- 순서 보장한다.
- Elasticsearch에 저장한다.
- Elasticsearch는 여러 개의 node로 이루어진 solution이다.
- 색인할 때 문지기 하는 node가 있다. (Coordinate Node)
- 모든 데이터는 Coordinate Node로 들어오고, 이후 Data Node로 보낸다.
- Ingest Node를 통해 여기서도 데이터 정제가 가능하다.
- 클러스터를 구성한다.
- 데이터 Life-Cycle을 만들다.
- 검색 가능하다.
- 다양한 검색 API를 제공한다. (대소문자/띄어쓰기/조건, 패싯, 사전기반, 오탈자 보정, 연관어, 자동완성, 하이라이트)
- n-gram : 숫자를 파싱하는 것, 입력한 단어가 데이터 중 n개 단어만 일치해도 검색 결과를 반환하는 형태의 자연어 처리 방식, 비용이 많이 든다.
- 시각화
- 관리자 화면
- 데이터 관리를 위한 UI 제공
- 데이터 조회 및 관리 권한 설정
- 데이터 시각화
- 데이터 시각화 도구 제공
- 통계 분석을 위한 대시보드 제공
- 시계열 기반 데이터 분석
- 시스템 성능 모니터링
- 데이터 수집 현황 모니터링
- 서버 상태 모니터링
- 관리자 화면
(6) Elastic Stack
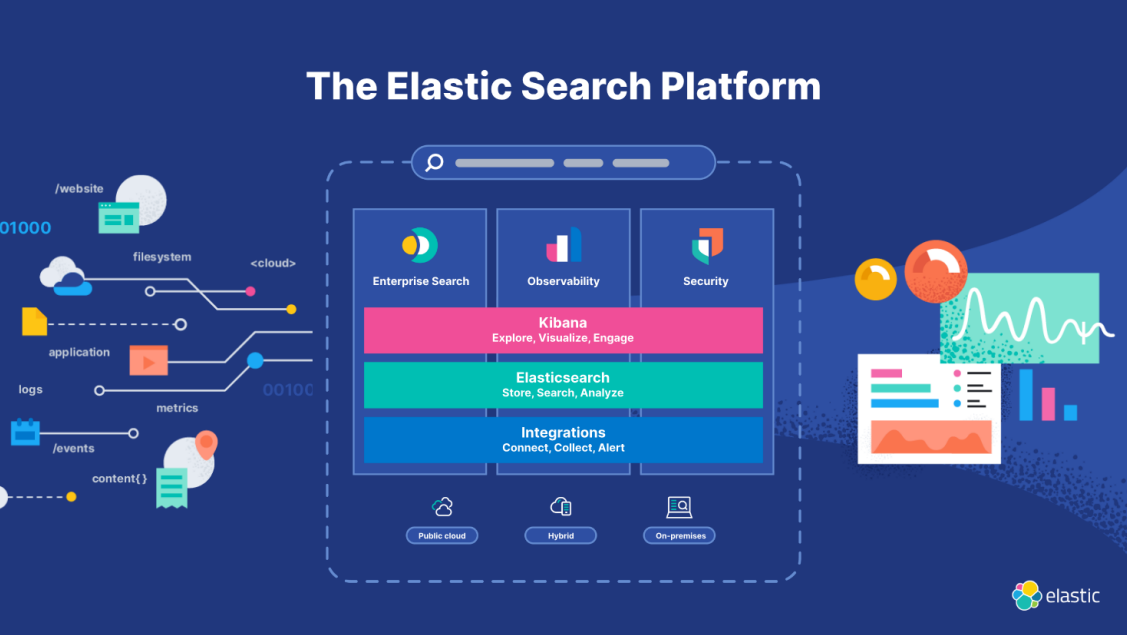
(7) Observability
- Logs, APM
- 로그 및 서비스 상태 통합 관리 UI 제공으로 개발자가 아닌 사람들도 확인할 수 있다.
- 그래프 등으로 시각화 할 수 있어 알아보기 용이하다.
- Security
- 보안 설정, 유지, 관제 및 조치
- SIEM, Endpoint Protection, Cloud Security 기능 제공
- 클라우스 서비스 사용 시 기본적으로 보안이 들어가 있으므로 크게 신경 쓸 필요 없다.
- Highlighting 8점대 version
- 속도 및 성능 향상
- KNN Search 고도화
- Test Embed 지원 (내부에서 test 가능하다.)
- 외부 PyTorch 모델을 지원한다.
- NLP 작업이 추가되었다.
- Application Search가 추가되었다.
- 스택 보안이 간소화 되었다.
- 보안이 필수다.
(8) Cluster Monitoring
- 아키텍쳐별 모니터링 방안
- 클러스터가 잘 유지되고 있는지 잘 확인하는 기능 (Self monitoring)
- Cluster 안에 node가 여러 개 있으므로 하나가 죽으면 다른 노드가 알려준다. = 자체 모니터링
- Monitoring Cluster을 구축한다.
- Beats 설치를 통한 로그를 수집한다.
- Elastic Agent를 통한 로그를 수집한다.
- 자원 및 모니터링 목적에 맞는 구성이 필요하다.
- 클라우드 매니지먼트 UI에서 모니터링을 한다.
(9) ILM
- 데이터의 수명주기 관리 = 인덱스 수명 주기 관리 = ILM (Index Kifecycle Maganement)
- Hot vs Warm vs Cold Node가 있다.
- Hot Node : 활발하게 인덱싱과 검색이 일어나고 있는 index이다.
- Warm Node : 자주 사용하지 않는 데이터를 가리키며 Query 빈도가 낮고 인덱싱이 잘 일어나지 않는 index이다.
- Cold Node : 검색을 하진 않지만 데이터 보존기간 정책상 보관이 되고 있는 index이다.
(10) Space & Use & Role
- 사용자별로 접근 권한을 제어한다.
- User와 Role, Space를 적절하게 구분해야 한다.
이와 관련된 실습은 아래 링크로 확인하실 수 있습니다.
[실습] 데이터 관리 - Roles, User, Space, ILM, Snapshot, Connector — y-seo의 딩코 기록들 (tistory.com)
[실습] 데이터 관리 - Roles, User, Space, ILM, Snapshot, Connector
데이터 관리 실습 실습 : 데이터를 관리하는 실습을 진행한다. 상세 내용 : 권한 만들기, 유저 만들기, ILM 생성하고 부여하기 1. 권한 만들기 (1) Elasticsearch > Stack Management > Roles 에서 역할들을 확인
y-seo.tistory.com
(11) Snapshot
- 다른 안전한 곳에 저장하는 것
- Hot, Warm, Cold 상관 없이 특정 부위의 데이터를 다른 공간에 복사하는 것
(12) 자격증
- ElasticSearch 엔지니어
- 쿼리 작성하는 역량을 많이 본다.
- 관리도 잘해야 한다.
- 기업에서 많이 쳐주고 많이 딴다.
- 데이터 분석가
- Kibana의 Dashboard를 만들 수 있는지를 본다.
2. Elastic Cloud
- On-premise : 기업 자체에서 서버를 직접 설치하여 사용하는 방식이다.
- VM : 물리적 하드웨어 시스템에 구축되어 자체 CPU, 메모리, 네트워크 등을 갖춘다.
- Cloud는 IaaS, PaaS, SaaS 중 하나의 서비스를 사는 것이다.
- IaaS : 서버, 스토리지, 네트워크를 가상화 환경으로 만들어 필요에 따라 인프라 자원을 사용할 수 있게 하는 서비스이다.
- PaaS : 애플리케이션 개발, 테스트, 배포 및 관리를 위한 플랫폼이다.
- SaaS : 사용자들에게 클라이언트 애플리케이션을 인터넷을 통해 제공하고 관리하는 방식이다.
- 주로 SaaS 환경에서 제공한다.
(1) HA (고가용성)
- Cluster이라고도 한다.
- 여러 개 중 하나가 죽어도 다른 것들을 통해 서비스를 쓸 수 있다.
- 3개 이상의 Cluster을 권장한다.
- Cluster : 똑같은 구성의 여러 대의 서버를 병렬로 연결할 상태
- HA : 고가용성을 유지하며 지속적으로 작동할 수 있는 능력을 갖고 있는 것
- 이중화 : 두 대의 서버 컴퓨터를 연결한 상태
| 클러스터 | 이중화 | |
| 연결한 서버 수 | 2개 이상 | 2개 |
| 사용 이유 | 고성능 기능 제공 | 장애 발생 시 예방 |
| 장애 발생 시 기능 유지 | 유지 | 유지 |
| 분산 처리 | 작업을 여러 노드에 분산 후 성능 향상 | 작업을 여러 노드에 분산 후 성능 향상 |
| 확장성 | 필요에 따라 확장 및 축소 가능 | 확장 및 축소가 제한적 |
(2) Cloud가 제공하는 편의 기능
- UI 중심의 간편한 조작으로 넓은 기능을 지원한다.
- 전문가가 아니어도 사용할 수 있다.
- 보안 기능을 기본으로 제공한다.
- 365일 24시간 온라인 기술을 지원한다.
- AWS와의 연결을 추구한다.
(3) Elastic Agent
- 한 번 설치하면 모든 데이터를 Elastic으로 보내준다.
- 장점
- 서로 다른 데이터 유형을 관리한다.
- 서로 다른 기종 및 환경에 산재하는 데이터를 통합 모니터링한다.
- 데이터 소스 추가/삭제 시 유연하게 대처한다.
- 종류
- Filebeat
- Metricbeat
- Winlogbeat
- Heartbeat
- Security
- APM
- Fleat
- Agent의 상태를 중앙집중식으로 관리한다.
- Fleet에 들어온 데이터는 그룹식으로 묶는다.
- APM
- APM 서버가 필요하다.
- 클라우드를 사용하면 별도 설치가 필요없다.
- On-prem를 사용하면 직접 설치해야 한다.
'Cloud > ElasticSearch' 카테고리의 다른 글
| [실습] Elastic APM 사용하여 접속 기록 수집하기 (0) | 2023.12.28 |
|---|---|
| [실습] Elastic으로 데이터 시각화 하는 방법 (Visualize Library, Dashboard) (0) | 2023.12.28 |
| [실습] 데이터 관리 - Roles, User, Space, ILM, Snapshot, Connector (1) | 2023.12.28 |
| [이론] 데이터 전처리, 색인 관리, 시각화 (0) | 2023.12.28 |
| [실습] Elasticsearch 실습 - logstash와 metricbeat 사용하기 (1) | 2023.12.27 |