![[이론] 데이터 전처리, 색인 관리, 시각화](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcqzjCb%2FbtsCG4ZqHpH%2FCuOJB5xegY8aMzv5d4Kn2K%2Fimg.png)
1. Elastic 데이터 기본 구조
(1) 클러스터 구조
클러스터의 구조는 아래와 같다.

(2) 노드
- 클러스터를 구성하는 단위 중 하나
- elasticsearch onprem으로 설치할 수 있다.
- 노드는 클러스터로 가용성 때문에 묶어주어야 한다. 노드 하나가 죽어도 다른 노드가 가동될 수 있도록 하기 위함이다.
- 노드는 최소 3개 이상인 홀수 개를 설정해야 한다. 3개 이상이 권장된다.
- 서버 당 노드는 1개이다.
- 클라우드 생성 시에 설정한다.
- 별도 설정이 없을 때 http port #는 9200, tcp port #는 9300이다.
- 클러스터를 여러 개 두어 통신 가능하다.
- cluster.yml에 클러스터 번호를 작성해주어 구분하여 접근 가능하다.
(3) 인덱스 구조
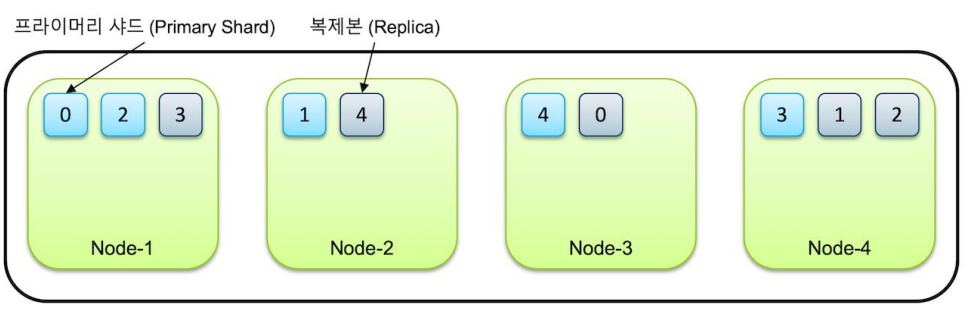
- 테이블과 동일한 개념이다.
- 인덱스의 기본 단위는 샤드(Shard)이다.
- 하나의 노드에 여러 개의 샤드가 있다.
- 샤드로 여러 개로 쪼개면 검색할 때 속도가 향상된다.
- 샤드가 5개이면 인덱스 하나를 저장할 때 5개로 쪼개서 저장하는 것이다.
- 색인할 때 더 빠르게 들어가게 한다. 한 곳에 5개가 기다리는 것이 아니라 나눠서 빠르게 들어가기 때문이다.
- 처음 생성되 샤드는 Primary라고 하고, 이후 생성된 복제본은 Replica라고 한다. 이 둘은 완전히 동일한 내용이다.
- 복제본을 사용하는 경우는 안정성 때문이다. 하나가 죽어도 복제본이라도 살기 위해서이다.
- 0끼리, 1끼리 등 같은 숫자끼리 한 노드에 들어가지 않는다.
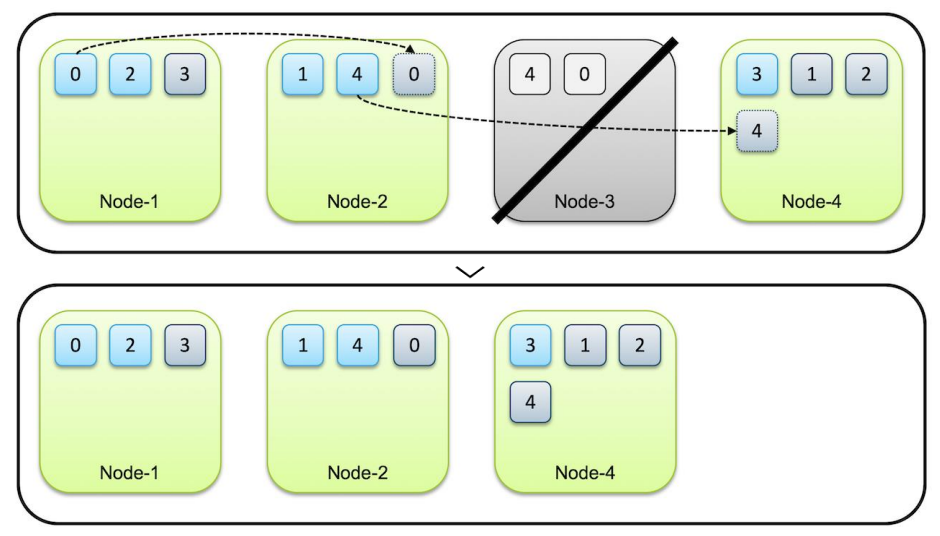
- 많이 복제할수록 장애가 더욱 발생하지 않겠지만, 공간 때문에 노드 개수 이상으로 복제하지 않는다.
- 노드 개수 이상으로 복제하면 클러스터의 안정성을 위협 받는다. 노드가 unassigned가 되기 때문에 cluster가 yellow(건강하지 않다)로 전환되며 이는 red(재난상황)로 바뀔 수도 있기 때문에 green으로 유지하는 것이 좋다.
- 처음 0~4의 샤드가 들어가는 경우는 랜덤이다. 중복만 되지 않으면 된다.
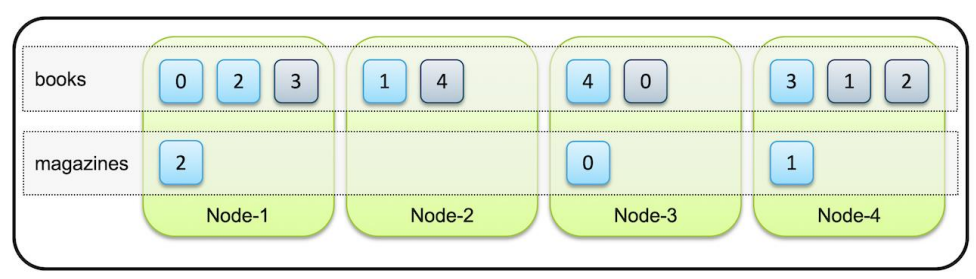
- 예시
- magazines는 replica가 없다. primary 3이다. = 3P0R
- books는 5 primary이고 replica가 1이다. = 5P1R
(4) 노드의 역할
- 노드 별로 역할이 다르게 주어진다.
- 역할은 한 노드에 중복되어 부여될 수 있다.
- 역할 목록
- master : master가 없다면 cluster가 실행되지 않는다. 따라서 master은 1개 이상 존재해야만 한다. master가 여러 개이면 master 중 하나가 선출되어 행동하고 나머지는 master 후보 노드가 된다.
- data : 앞에 data 수식어가 붙으면 데이터를 저장하는 역할을 한다.
- data_hot
- data_cold
- ingest
- remote_cluster_client
- transform
- ml
- data_frozen
- data_warm
- data_content
- Coordinate Node : 문지기 역할, 없다면 모든 node가 문지기 역할을 가진다. coordinating은 coordinating 역할만 가질 수 있으므로 다른 역할을 아무것도 적지 않는다.
- master 노드는 별을 붙여 주로 표현한다.
- master, master 후보 노드는 홀수 개로 설정할 것이 권장된다. 짝수 설정 시 split brain이 발생될 수 있다.
- split brain
- 가정 : 한 클러스터에 속한 node들은 master 후보 노드의 개수를 알고 있다.
- master 후보 노드가 짝수 개일 때 : 다른 클러스터와 연결이 끊어질 경우, 각각의 클러스터의 master 후보 노드가 전체 master 후보 노드의 절반이 되기 때문에 master로 선출한다. 이런 현상이 각각의 클러스터에서 동일하게 발생하기 때문에 다시 통신이 이루어졌을 때 master을 인식하지 못하는 충돌이 발생한다.
- master 후보 노드가 홀수 개일 때 : 다른 클러스터와 연결이 끊어질 경우, 하나의 클러스터가 가진 master 후보 노드의 개수가 전체 master 후보 노드의 개수의 절반보다 넘기 때문에 master가 선출된다. 다른 클러스터는 master 후보 노드의 개수가 전체 master 후보 노드의 개수의 절반을 안 넘기 때문에 master로 선출하지 않고 대기한다. 따라서 전체적으로 하나의 master만 선출되므로 split brain이 일어나지 않는다.
(5) 인덱스 기본 구성
- 모든 인덱스가 가지고 있는 정보 단위 목록
- Setting : 인덱스가 가지는 기본 설정
- primary shard는 재설정 되기 전까지 변경되지 않는다.
- replica shard 수는 dynamic하게 설정 가능하다. (Ex. 0~2개)
모듈 설명 number_of_shards Primary shard 수 number_of_replicas Replica shard 수 refresh_interval Index 변경 사항 적용 주기 default_pipeline 데이터 수집 시 적용 pipeline analysis analyzer, tokenizer, token filter 정의 - Mappings : 필드 스키마
- keyword는 통으로 한 글자로 인식하는 것이다. 집계(aggregation)에 사용하기 좋다.
- text는 띄어쓰기 단위로 쪼개지는 것이다.
필드 타입 숫자 Integer / Long / Double 등 날짜 Date 문자열 Text / Keyword Geo Data Geo_point / Geo_shape - Aliases : 별칭, 옵션
- 특정 패턴의 인덱스를 한 번에 조회할 수 있다.
- 다중/단일 인덱스 별칭이 사용 가능하다.
- 한 인덱스에 여러 별칭 사용이 가능하다.
2. 데이터 전처리
(1) 인덱스 색인 전 설정
- Index 구성을 미리 설정하는 Template이 있다.
- 아직 색인되지 않는 인덱스를 위해 만들어 놓는 틀이며 해당하는 패턴의 인덱스는 템플릿의 설정을 따라 색인된다.
- 효율적인 인덱스 관리를 위해 꼭 필요한 절차이다.
(2) Logstash Queue
- persistent queue는 확정적인 저장 지점을 저장한다.
- dead letter queue는 최소한의 복구 정책이고 persistent queue는 확장된 복구 정책이다.
(3) Watcher & Alert
- Rule
- 사람이 24시간 밀착하여 확인할 수 없으니 설정하는 것
- rule에 따른 alert이 필요하다. 데이터 관리의 마지막은 rule과 alert이다.
- Watcher
- 쿼리 작성이 필요하다.
- 복잡한 조건에 적합하다.
- Rule과 Alert
- 쿼리를 포함한 인터페이스를 지원한다.
- 간편한 커넥터를 연동한다.
(4) Alert Flow
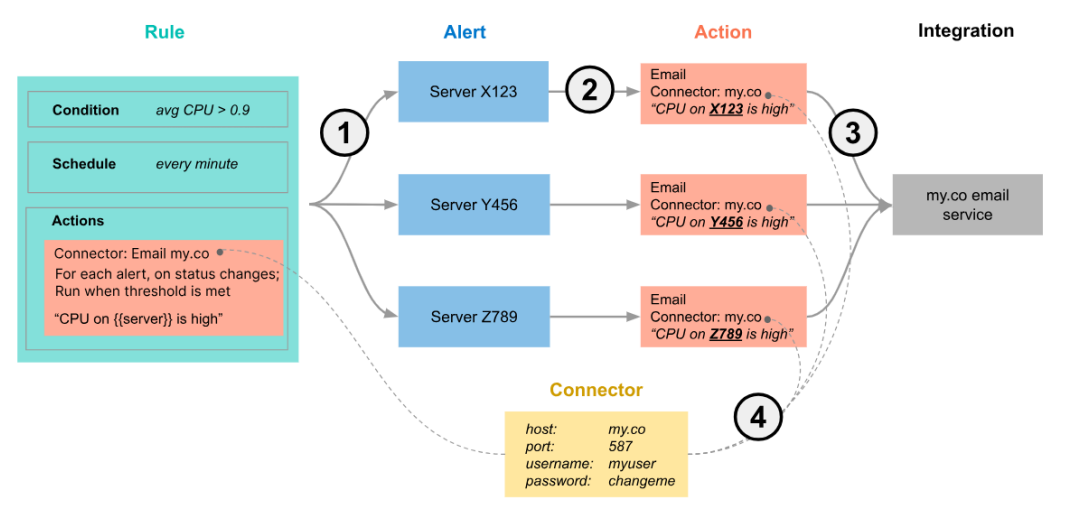
CPU의 평균값이 0.9 초과이면 Alert이 된다.
Alert에 따른 Action을 설정한다.
Alert은 다중조건은 불가능하다. 다중 액션은 가능하다.
Rule : Action = 1 : N
(5) Rule 목록
- Stack Rules
- 조건을 충족해야 날아가는 Rule
- DSL 쿼리 기반 조건 충족 도큐먼트, 인덱스 상태, 필드 값 모니터링 Rules
- Elasticsearch query
- Index threshold
- Transform rules
- Tracking containment
- Observability Rules
- APM, Log, Metrics, Stack Monitoring, Uptime 관련 Observability rules
- APM and User Experience
- Logs rules
- Metrics rules
- SLO burn rate rule
- Uptime ruless
- APM, Log, Metrics, Stack Monitoring, Uptime 관련 Observability rules
- ML Rules
- ML 기반 rules [beta]
- Anomaly detection
- Bucket
- Record
- Influencer
- ML 기반 rules [beta]
(6) Connetors
- Action 기반
- 내/외부 Alert를 위한 것이다.
3. 데이터 시각화
- 시스템 성능을 모니터링하는 기능이다.
- 데이터 수집 현황 모니터링 : 실시간 수집되는 데이터의 수집 상태 모니터링을 제공한다. 현재 잘 들어오고 있는지 확인하는 작업, alert 기능과 연관되어 있다.
- 서버 상태 모니터링 : Elasticsearch 운영 시스템 서버 성능을 실시간 모니터링하는 기능을 제공한다. CPU 등과 같은 것들이 대상이 된다.
- 데이터 시각화
- 다양한 시각화 도구가 있다. (데이터 테이블, 라인 그래프, 지도 등)
- 데이터 통계 및 분석 기능 시각화 도구를 제공한다. (태그 클라우드 등)
- 시계열 기반 데이터 분석이 가능하다. (시간대별 변화하는 데이터 및 수치를 그래프로 제공한다.)
- APM
- processing이 잘 되고 있는지 보는 것이다.
- 자동 dashboard를 만들어준다.
'Cloud > ElasticSearch' 카테고리의 다른 글
| [실습] Elastic APM 사용하여 접속 기록 수집하기 (0) | 2023.12.28 |
|---|---|
| [실습] Elastic으로 데이터 시각화 하는 방법 (Visualize Library, Dashboard) (0) | 2023.12.28 |
| [실습] 데이터 관리 - Roles, User, Space, ILM, Snapshot, Connector (1) | 2023.12.28 |
| [실습] Elasticsearch 실습 - logstash와 metricbeat 사용하기 (1) | 2023.12.27 |
| [이론] ElasticSearch 개념, 특징, 기능 (0) | 2023.12.27 |