![[실습] Elasticsearch로 inverted index 추출하기, reindex 하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FWnEjf%2FbtsCSBnAcLx%2Fuw4jsRp2Ttl3GWZDM8p8dk%2Fimg.png)
실습 개요
목적 : 데이터셋에 검색을 했을 때 내가 원하는 내용만 나올 수 있도록 튜닝하기
제목 : Elasticsearch를 사용하여 데이터로부터 적절한 inverted index를 추출한다.
1. Elasticsearch에 data 넣기
(1) Elasticsearch에 로그인한다.
(2) Machine Learning > File 에 접근하여 데이터를 import한다.
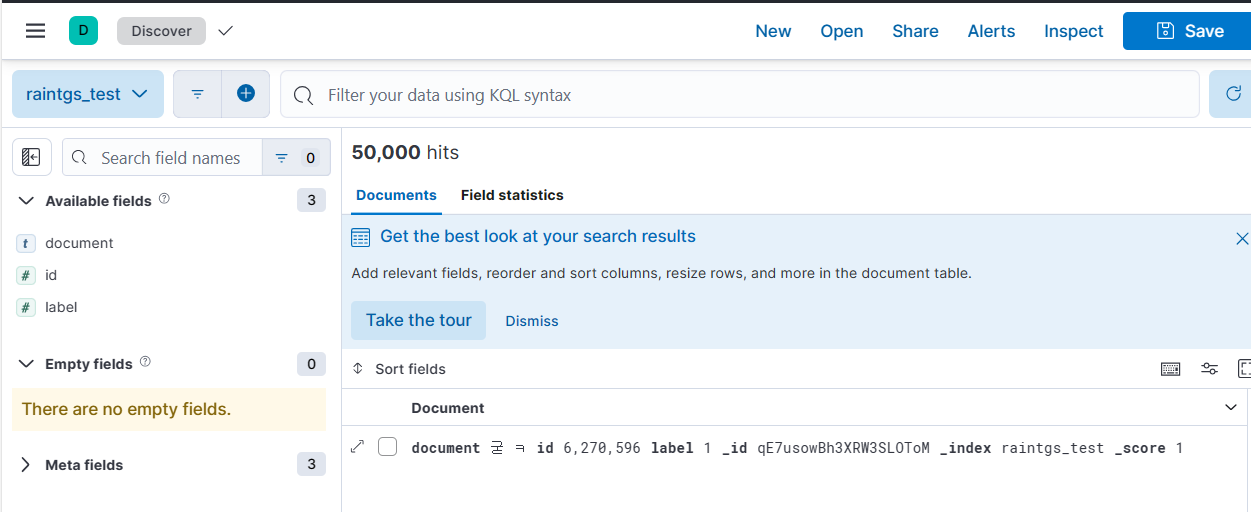
(3) Discover 메뉴에서 방금 추가한 데이터셋을 선택하면 내용을 볼 수 있다.
2. Inverted Index 확인해보기
(1) DevTools > Console에 접근한다.
(2) analyze API를 이용해 테스트한다.
POST /_analyze
{
"text" : "The quick brown fox jumps over the lazy dog",
"analyzer" : "standard"
}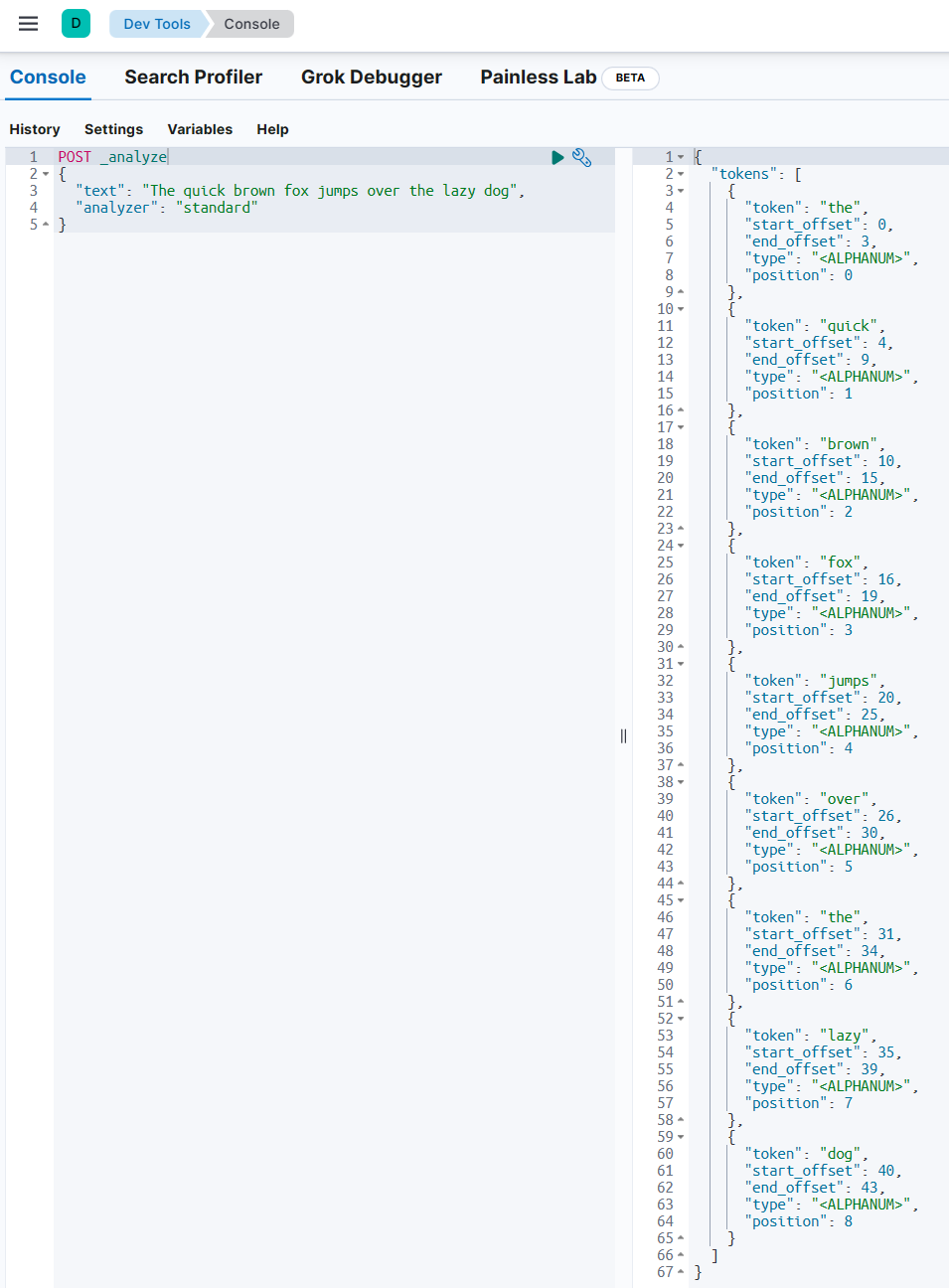
원본 텍스트를 standard라는 analyzer에 통과시켰을 때 term(token)들이 생성된다. 이런 term들에 추후 doc ID가 붙는다.
3. 여러 가지 Built-in Analyzer 사용하기
(1) english analyzer 사용하기
POST _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"analyzer": "english"
}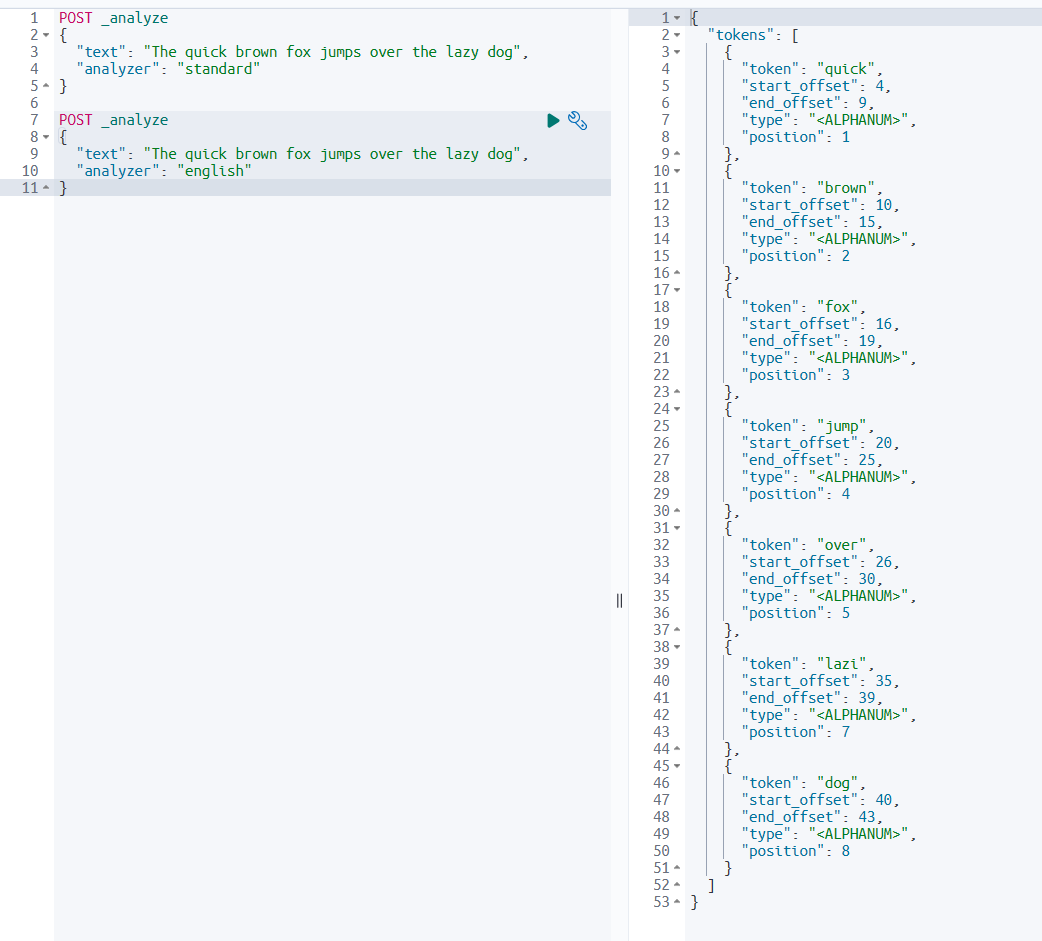
- 순서대로 token이 만들어지지 않는다.
- the 같이 사람들이 안할 것들은 token에 포함시키지 않는다. → 저장공간이 절약된다.
- 영어를 대상으로 analyzer한다.
- 복수형도 기본형으로 바꾸어 token으로 뽑는다. → 진행형, 과거형도 마찬가지이다. (Ex. jump)
- 활용형이 기본형과 다른 단어들도 시스템 내에 그 규칙과 예시가 저장되어 있으므로 검색에 문제가 없다. (Ex. buy)
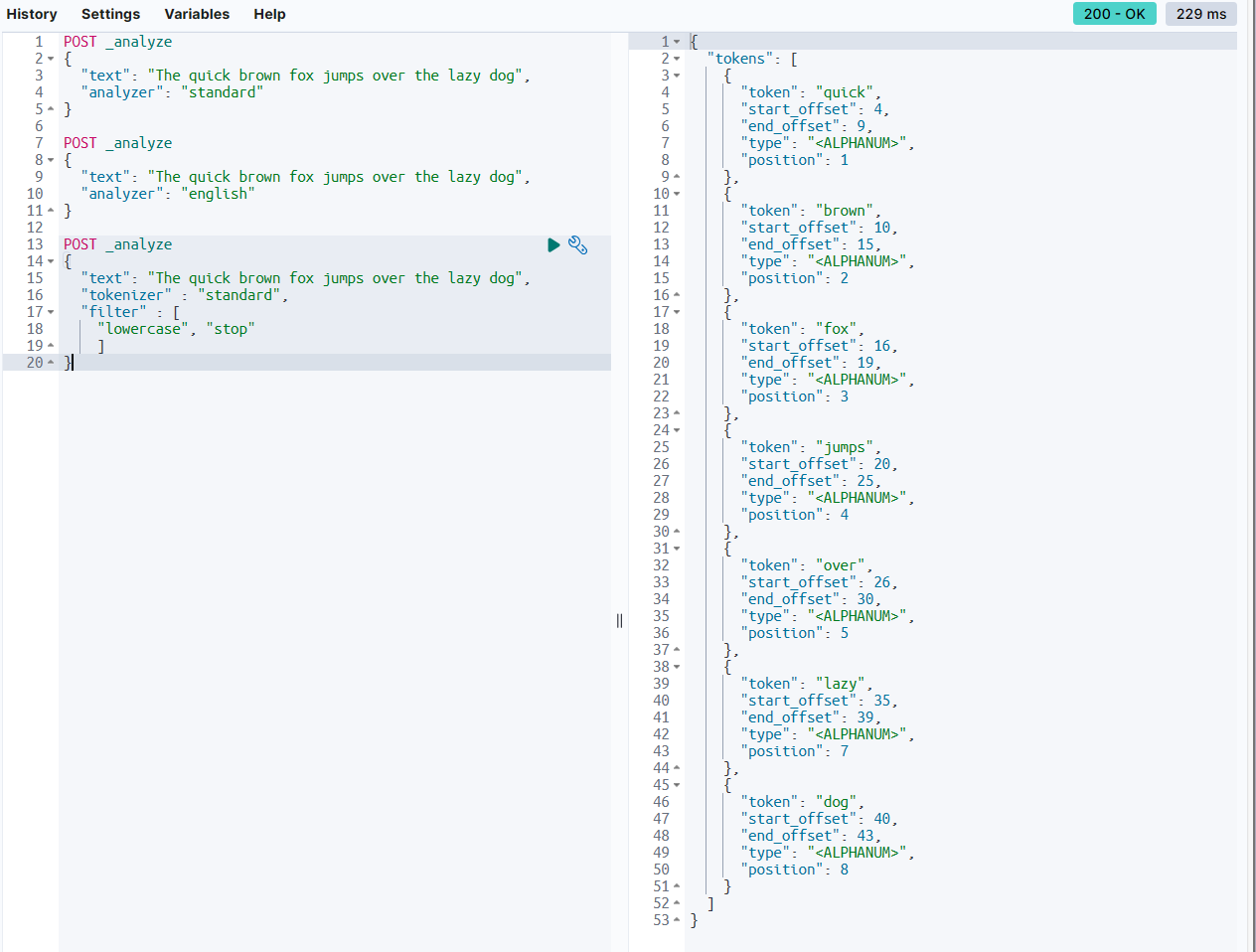
(2) Tokenizer와 Token Filter 지정하기
POST _analyze
{
"text": "The quick brown fox jumps over the lazy dog",
"tokenizer" : "standard",
"filter" : [
"lowercase", "stop"
]
}
(3) Nori Analyzer 사용하기
POST _analyze
{
"text" :"인생 최고의 영화",
"analyzer" : "nori"
}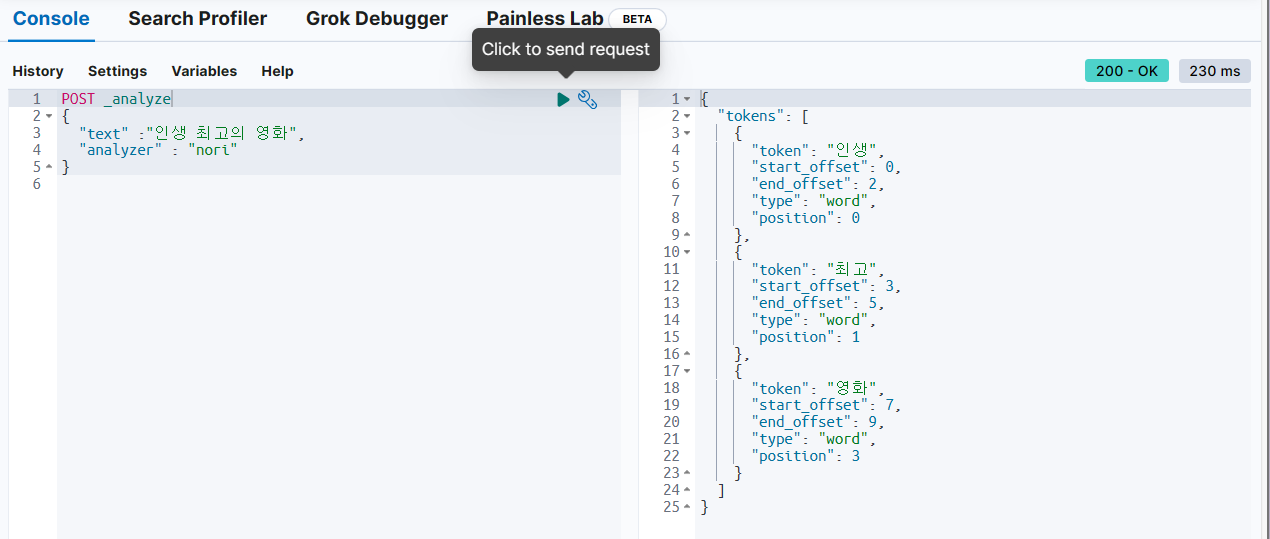
만약 Error가 난다면 Nori plug-in을 elasticsearch 페이지 설정에서 설치해주어야 한다.
(4) nori 관련 tokenizer, filter 지정하기
POST _analyze
{
"text": "사천만 國民이 다 봐야 하는 영화 입니다. ",
"tokenizer": "nori_tokenizer",
"filter": [
"nori_part_of_speech","nori_readingform","nori_number"
]
}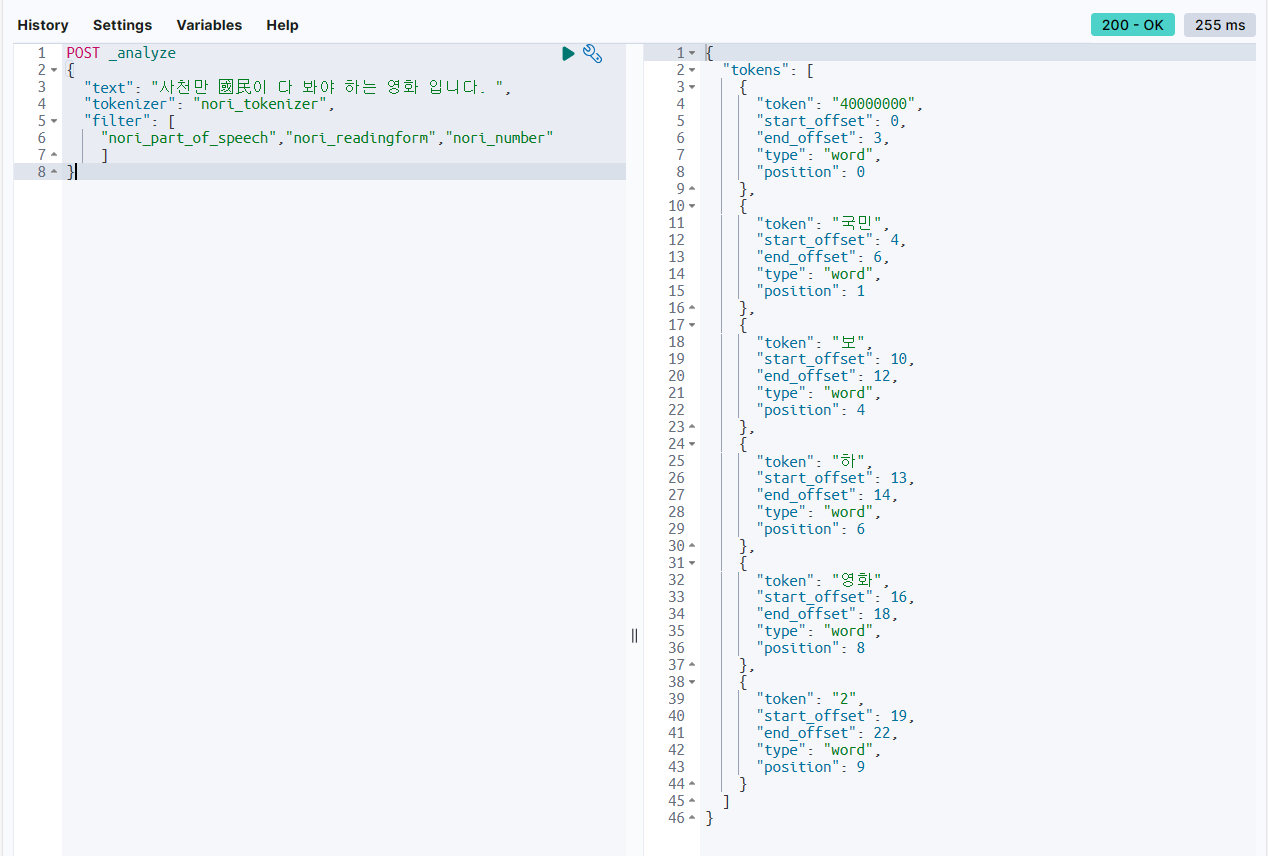
nori_tokenizer은 한글을 token으로 분리한다. (현재로서는 유일하다.)
nori_part_of_speech는 한글 한정으로 불용어(Ex. 조사, 부사)를 제거한다.
nori_readingform은 한자를 한글로 바꾼다.
nori_number은 숫자를 읽은 한글을 숫자로 바꾼다.
(5) nori_tokenizer의 옵션 사용하기
DELETE nori_sample
PUT nori_sample
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"nori_user_dict": { //tokenizer custom
"type": "nori_tokenizer", //기존에 있는 것을 가져오기
"decompound_mode": "mixed", //option
"discard_punctuation": "false", //option
"user_dictionary_rules": ["세종시 세종 시"] //추가 rule 등록, 사용자 정의 사전
}
},
"analyzer": {
"my_analyzer": { //analyzer name
"type": "custom",
"tokenizer": "nori_user_dict" //tokenzier name
}
}
}
}
}
}
GET nori_sample/_analyze
{
"analyzer": "my_analyzer",
"text": "세종시."
}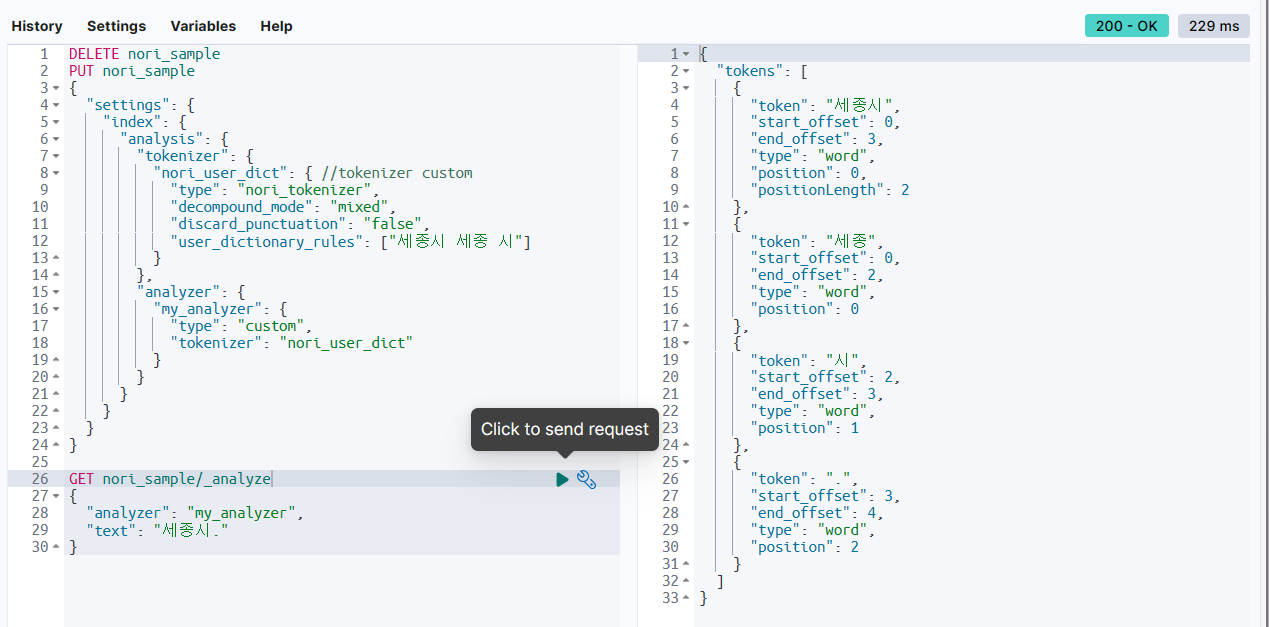
. token은 필요 없으므로 수정한다. discard_punctuation을 true로 한다.
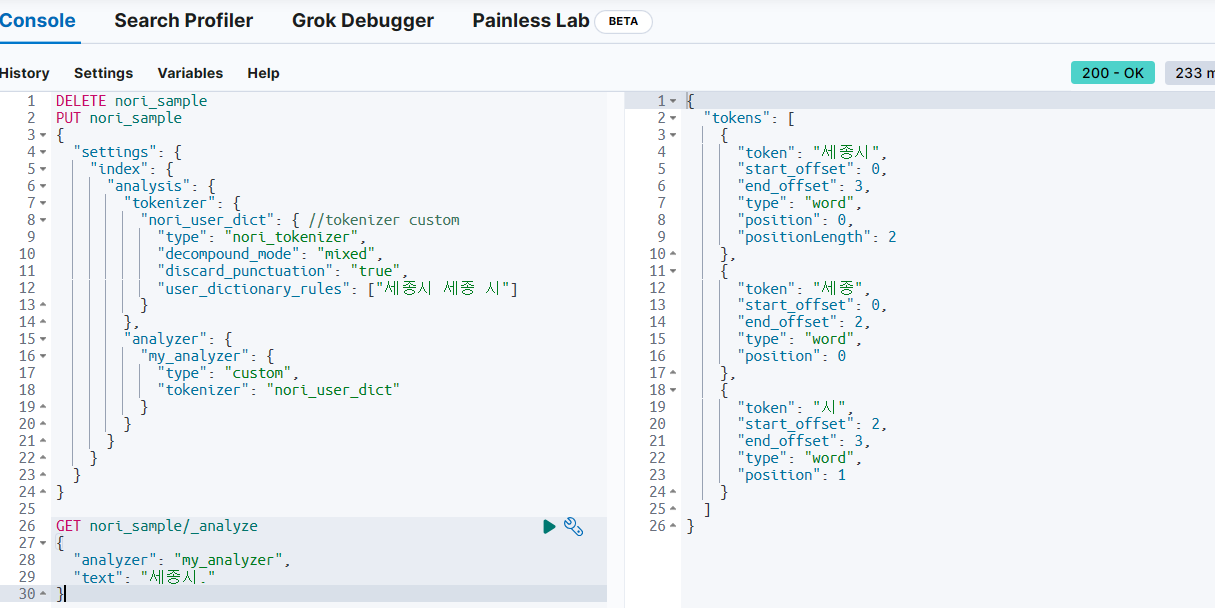
(6) nori filter의 option 지정하기
DELETE nori_sample
PUT nori_sample
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"nori_user_dict": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "false",
"user_dictionary_rules": ["세종시 세종 시"]
}
},
"filter": {
"my_posfilter": {
"type": "nori_part_of_speech",
"stoptags": [
"NR"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_user_dict",
"filter": [
"my_posfilter"
]
}
}
}
}
}
}
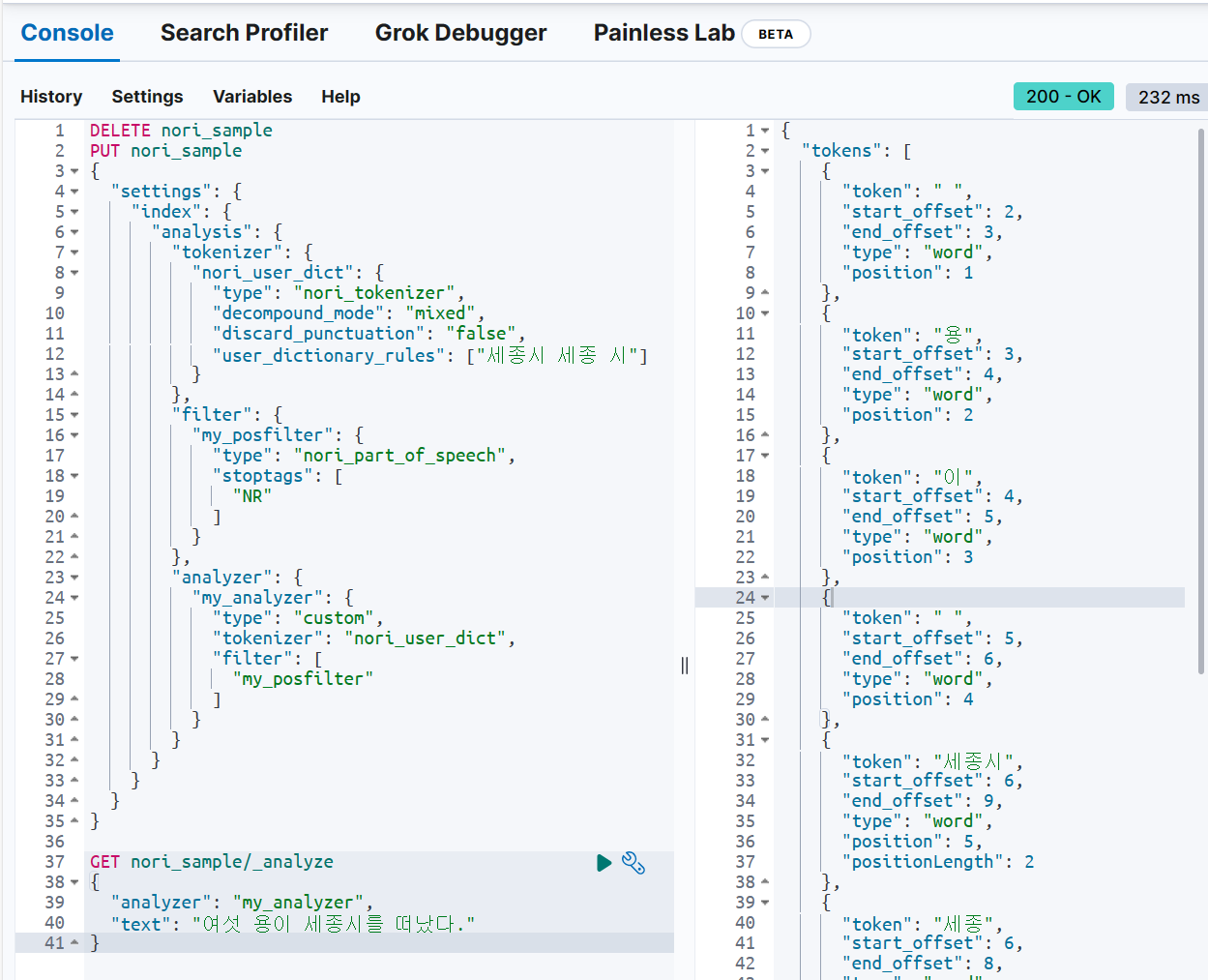
GET nori_sample/_analyze
{
"analyzer": "my_analyzer",
"text": "여섯 용이 세종시를 떠났다."
}
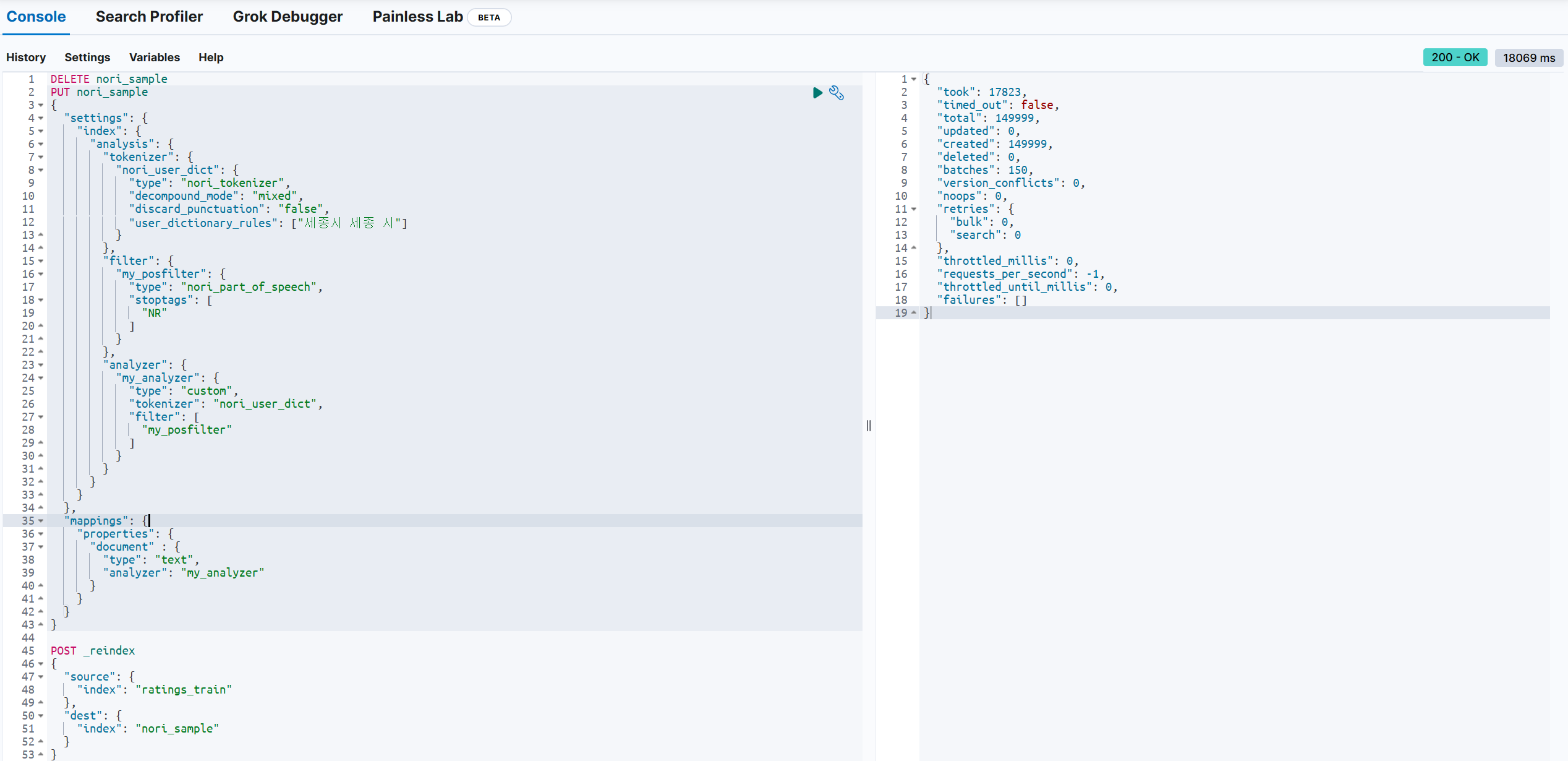
3. reindex 하기
reindex란 말그대로 인덱싱을 새로 한다는 뜻으로, 기존의 인덱스에서 새로운 인덱스로 새롭게 데이터를 색인하는 것이다.
(1) Devtools의 console에서 아래 코드를 실행한다.
DELETE nori_sample
PUT nori_sample
{
"settings": {
"index": {
"analysis": {
"tokenizer": {
"nori_user_dict": {
"type": "nori_tokenizer",
"decompound_mode": "mixed",
"discard_punctuation": "false",
"user_dictionary_rules": ["세종시 세종 시"]
}
},
"filter": {
"my_posfilter": {
"type": "nori_part_of_speech",
"stoptags": [
"NR"
]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_user_dict",
"filter": [
"my_posfilter"
]
}
}
}
}
},
"mappings": {
"properties": {
"document" : {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
POST _reindex
{
"source": {
"index": "ratings_train"
},
"dest": {
"index": "nori_sample"
}
}
(2) Discover 에서 Create a data view 를 클릭한다.
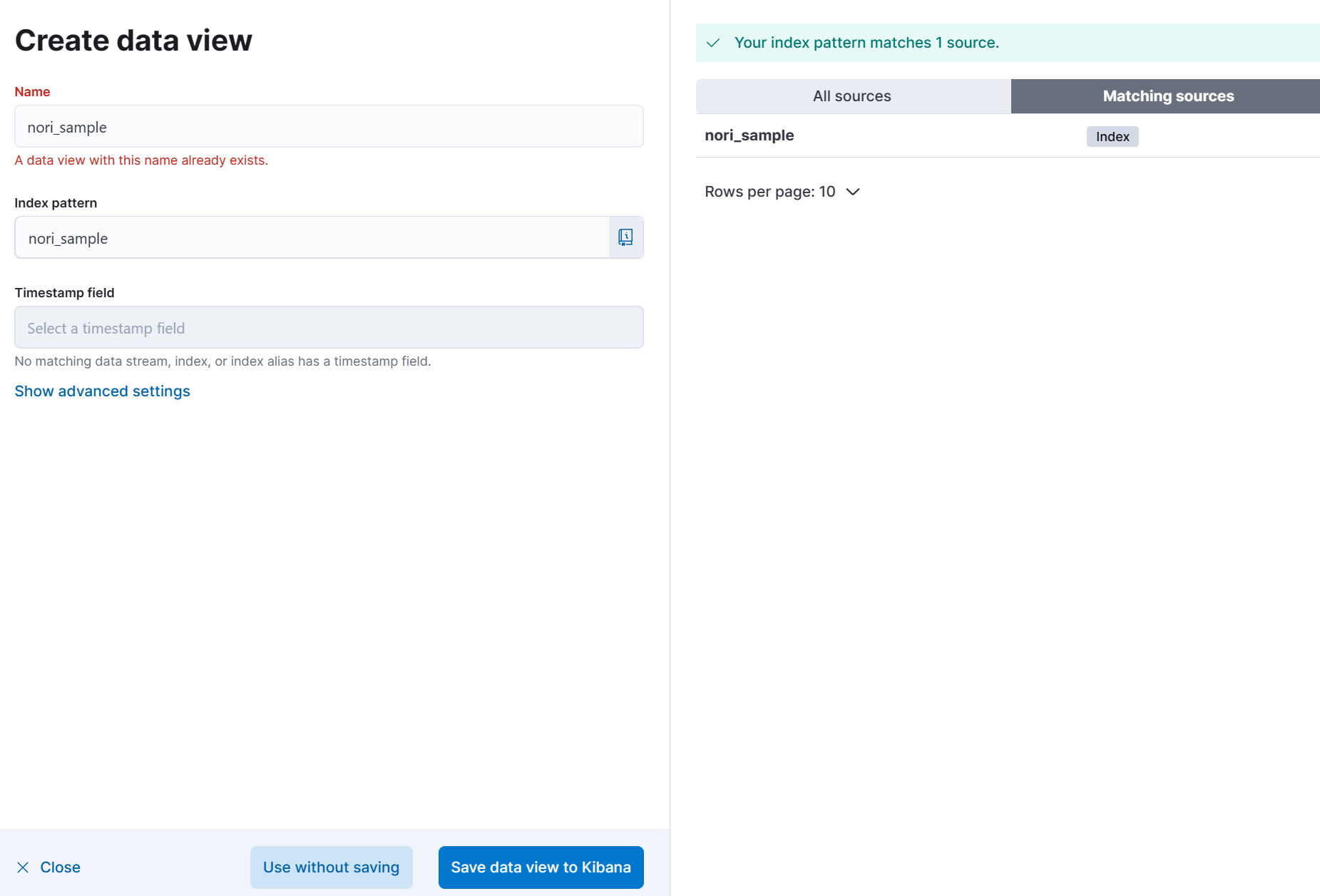
(3) 방금 생성한 index를 불러온다.
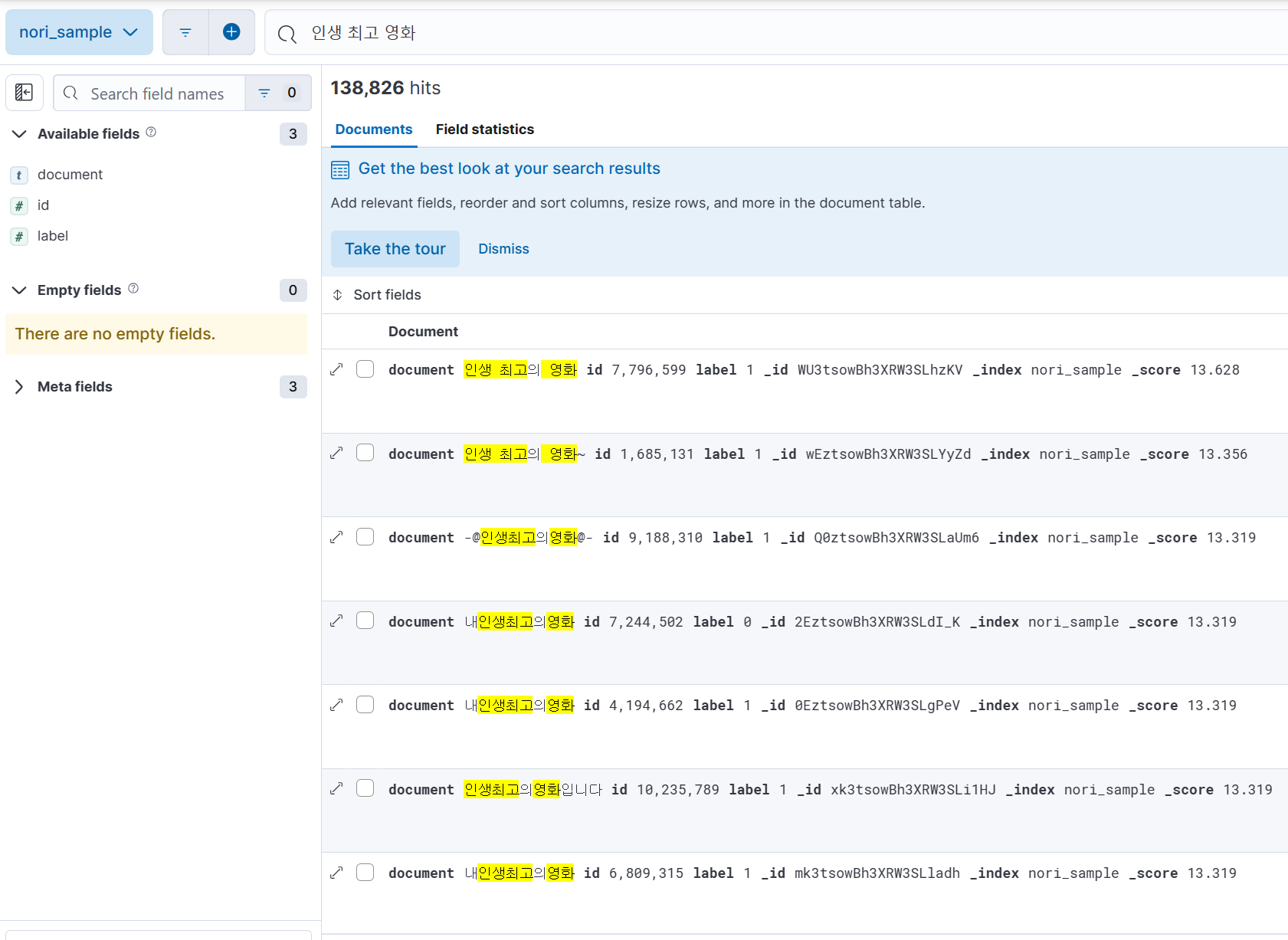
(4) 아래와 같이 검색 결과를 볼 수 있다.
'Cloud > ElasticSearch' 카테고리의 다른 글
| [실습] Elasticsearch Query 사용하기 (0) | 2023.12.29 |
|---|---|
| [개념] Elasticsearch Query (Query DSL, Aggregation) (0) | 2023.12.29 |
| [이론] Elasticsearch 형태소 분석기 (0) | 2023.12.29 |
| [실습] Elastic APM 사용하여 접속 기록 수집하기 (0) | 2023.12.28 |
| [실습] Elastic으로 데이터 시각화 하는 방법 (Visualize Library, Dashboard) (0) | 2023.12.28 |