Cluster
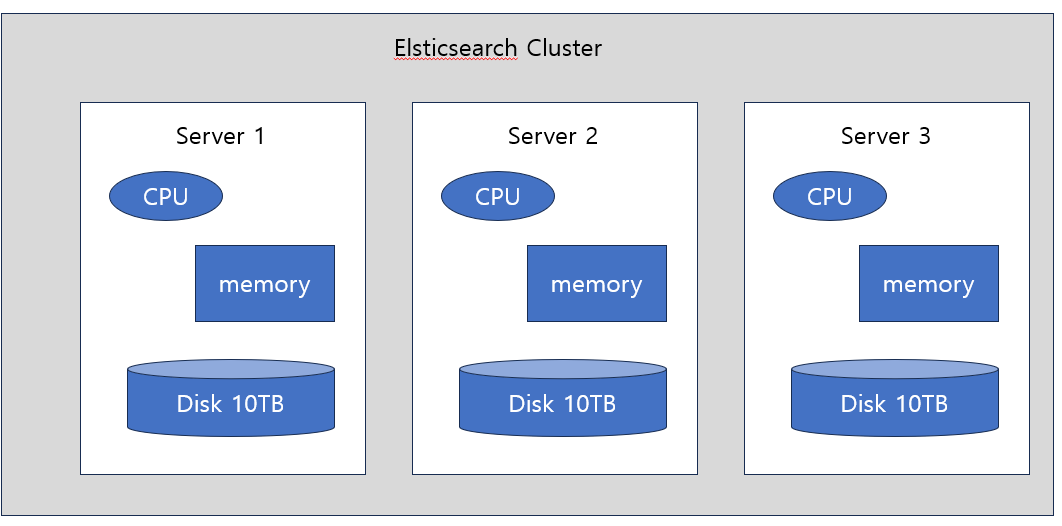
- Elaster search cluster는 분산처리 아키텍처이다.
- 외부에서 바라보면 하나의 서비스이지만 실제로는 안에 여러 개의 entity가 들어있다.
- Elasticsearch의 resource는 다음과 같다.
- CPU, Memory, Disk
- 위에 세 가지가 Elasticsearch 서비스를 운영한다.
- Elasticsearch lcuster 안에는 여러 개의 node가 들어있다.
Index & Cluster
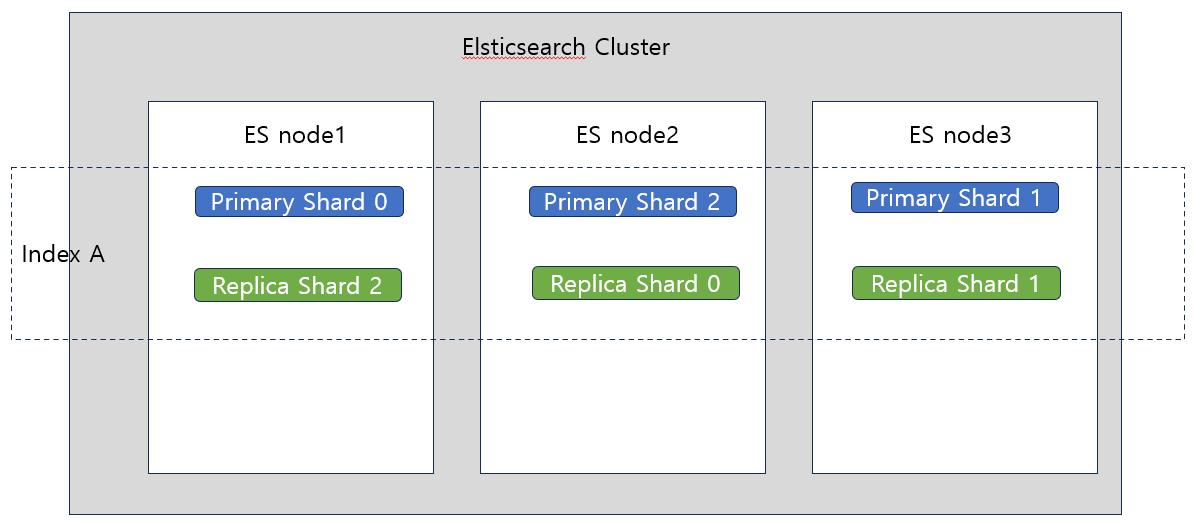
- Index : 데이터를 저장하는 단위
- 이는 분산처리 아키텍쳐에서 분산되어 저장된다.
- 하나의 인덱스는 여러 개의 Shard로 구성되어 있다.
- Shard 레벨로 각각의 node 안에 저장된다.
- Replica Shard : 이렇게 해야 특정 node가 죽었을 때도 다른 node의 Replica shard #가 작동하므로 서비스 제공에 문제가 없다.
Document
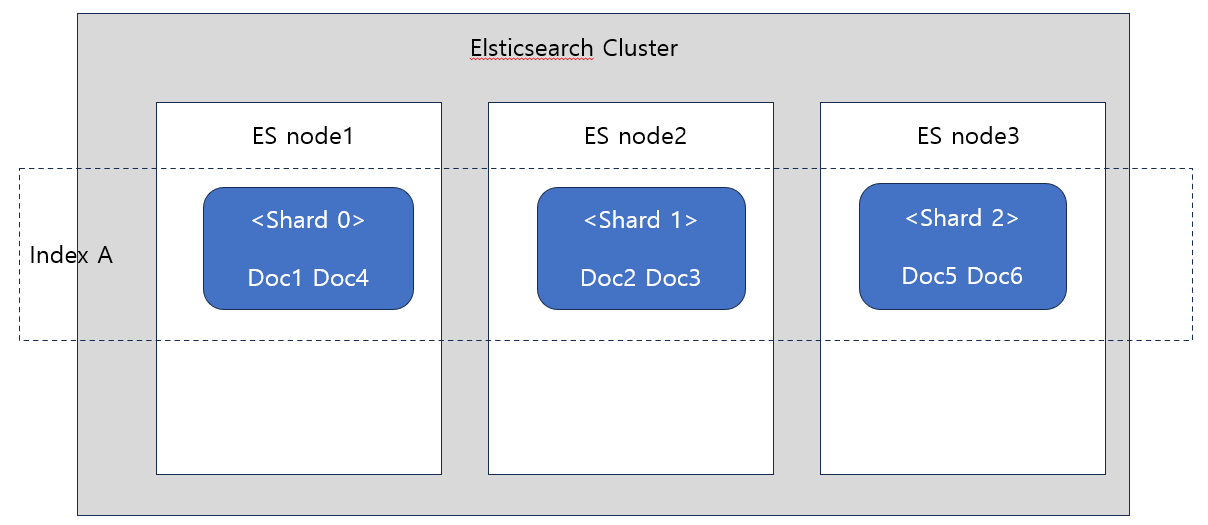
- Elastic에 있는 document는 json 객체이다.
- Document들이 index 안에 저장되고 index 안에는 shard가 있으므로 결국 shard 안에 document가 저장되는 것이다.
Segment
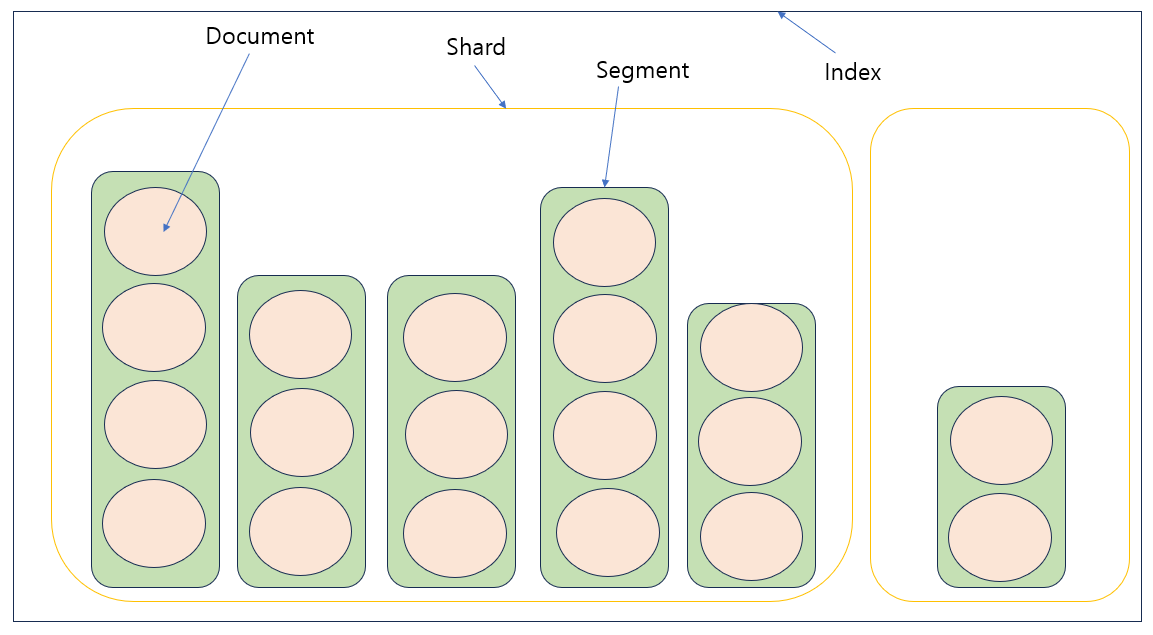
- Shard 안에는 여러 개의 segemnt가 있다.
- Segment 안에 여러 개의 Document가 저장되어 있다.
- 저장 : Disk에 file로 작성한다. =색인/인덱싱
- Disk에 file을 쓰고 읽는 작업은 cost가 많이 든다. 실은 준비 단계에서 overhead가 많다.
- 따라서 file을 적게 쓰는 것이 좋다.
- 위와 같이 해결해주는 것이 segemnt이다.
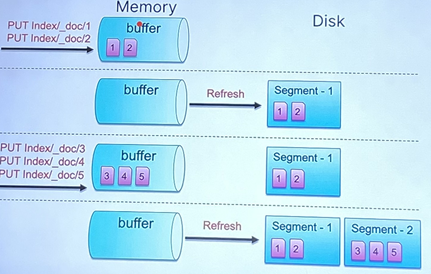
- File I/O가 여러 번 발생할 것을 segement로 묶어서 보내면 덜 발생할 수 있다.
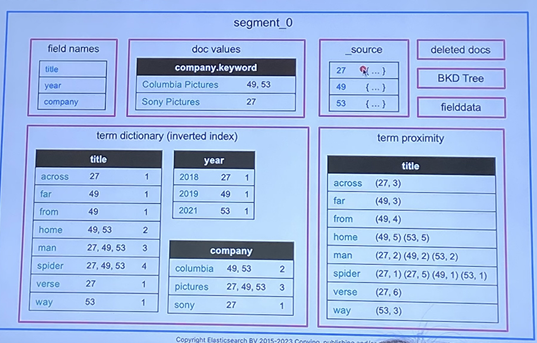
- Segement Structure
- document의 원본 데이터만 저장하는 것이 아니다.
- 추가 정보가 있어서 검색을 빠르게 하게 한다.
- inverted index : 이것을 잘 만들기 위해 형태소분석기를 사용한다. 검색을 하면 실제로 여기서 검색이 이루어진다.
- 검색 : 원본 데이터와 상관 없이 inverted index에서 검색이 이루어진다.
Inverted Index
- Elasticsearch는 Full Text(자연어 문장) 검색이 가능하다.
- 데이터에 접근할 때 가장 먼저 접근하는 것이 RDBMS이다.
- 여기서는 데이터를 테이블 형태로 저장한다.
- RDBMS의 인덱스는 특정 열을 기준으로 만든다.
- 내용을 검색하려면 인덱스를 LIKE 검색으로 한 row씩 찾아야 한다.
- 검색 시에는 모든 row를 확인하므로 테이블의 내용이 늘어날수록 검색에 걸리는 시간이 늘어난다.
- 따라서 “자연어에 대해 빠르게 검색하는 구조가 필요하다”는 결론에 도달한다.
- RDBMS의 row, column 구조는 적합하지 않다.
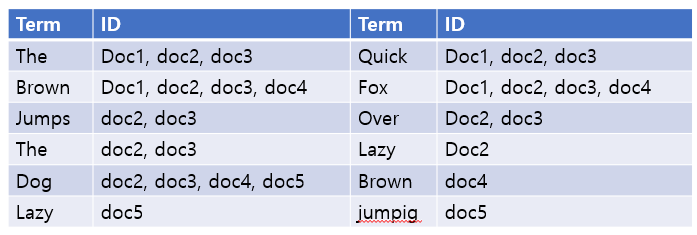
- 테이블 형태로 데이터를 저장하는 것이 아니라 검색 엔진에서는 inverted index라는 구조로 데이터를 저장한다.
- RDBMS와 반대 구조이다.
- 텍스트를 다 뜯어 검색어 사전을 만든다. (Term 이라고 한다.)
- n개 document에서 나오는 term만 검색한다. 그럼 나중에 해당하는 term의 리스트를 리턴한다. → 검색 속도가 ms로 줄어든다.
Elasticsearch 형태소 분석기 (Analyzer)
- inverted index를 잘 만드는 것이 관건이다.
- inverted index를 만들기 위해 Analyzer에 data를 통과시킨다.
- 텍스트 분석 과정 : 텍스트 분석은 Analyzer 이라고 하는 도구가 수행한다.
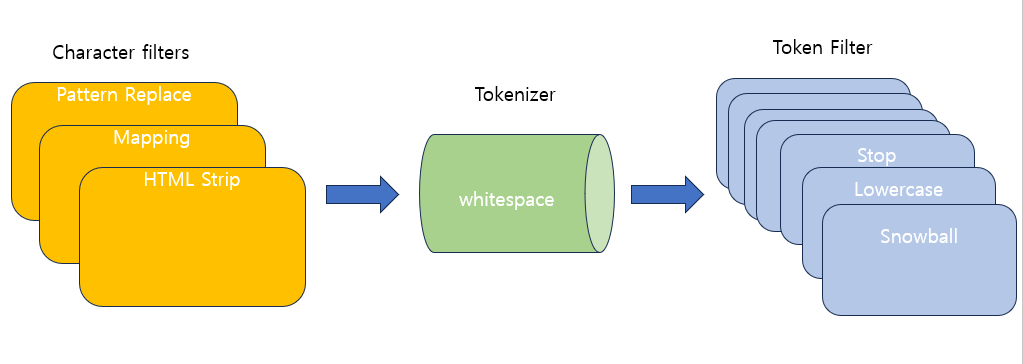
- Analyzer
- 캐릭터 필터 → 토크 나이징 → 토큰 필터
- 위 과정을 거치면 inverted index가 만들어진다.
- 캐릭터 필터 : 0개 이상
- 토크나이저 : 1개
- 토큰필터 : 0개 이상
Analyzer 구성
- Characer filter
- 원본데이터를 전처리한다.
- Elasticsearch에서 제공하는 Character filter는 3개뿐이다.
- HTML : <태그> 제거와 치환
- Mapping : 특수문자를 숫자로 치환
- Pattern : 전화번호 같은 패턴을 탐지하고 원하는 형태로 replacement
- Tokenizer
- 원본 데이터를 term 레벨로 쪼갠다. = 문장을 분리한다.
- 보통 Whitespace Tokenizer가 사용된다. (띄어쓰기 기준으로 자르기)
- 예시 사진
- 전체 텍스트를 inverted index에 들어갈 term 레벨로 쪼개는 역할을 한다.
- Token Filter
- Tokenized 된 Term들을 가공한다. = token에 대한 정제, 후처리를 한다.
- Lowercase Token Filter로 대문자를 소문자로 변환한다.
- 불용어(stopwords, 검색어로서의 가치가 없는 단어들)를 제거한다.
- ~s, ~ing 등을 제거한다.
- 동의어를 처리한다. → 합쳐준다. (Ex. quick & fast)
- 공식문서를 통해 어떤 Analyzer에 어떤 Filter가 있는지 확인할 수 있다. (https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-analyzers.html)
Built-in analyzer
Nori analyzer (한국어 형태소분석기)
- 단어 사전 기반의 분석이 필요하다. (Ex. 대학생선교회 = 대학생 + 선교 + 회)
- Korean (nori) analysis plugin | Elasticsearch Plugins and Integrations [8.11] | Elastic
- 구성 요소
- nori_tokenizer : 한글을 token으로 분리한다. (현재로서는 유일하다.)
- nori_part_of_speech token filter : 한국어 한정으로 불용어를 제거한다.
- nori_readingform token filter : 한자를 한글로 바꾼다.
- nori_number token filter : 숫자를 읽은 한글을 숫자로 바꾼다.
- nori_tokenizer 안에 사용할 수 있는 option들이 있다.
- decompound_mode, discard_punctuation, user_dictionary_rules
![[이론] Elasticsearch 형태소 분석기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FyRMwg%2FbtsCG4eBk8k%2FtxQE9rZBCTIqbhZDlRMhzK%2Fimg.png)